Summary
Ensembles of models are known to be more robust to adversarial attacks: it is harder to fool multiple models simultaneously. Transferability is a well-known property of adversarial examples that make it difficult to build robust ensembles. Prior attempts at training robust ensembles focus on diversifying the models to “shrink” the set of common adversarial examples.
Controlling the Lipschitz continuity effectively enhances the robustness of individual models against adversarial attacks. In our work, we investigate the effect of Lipschitz continuity on the transferability of adversarial examples. We observe that while decreasing the Lipschitz constant makes each model of the ensemble individually more robust, it increases the transferability rate among them which in turn hinders the overall ensemble robustness.
To resolve this adverse effect, we introduce our novel training paradigm, Layer-wise Orthogonalization for Training rObust enSembles (LOTOS), which orthogonalizes the corresponding affine layers of the models with respect to one another.
What we found
We start with a simple theoretical observation that motivates the adverse effect of lower Lipschitz constants for transferability of adversarial examples. We evaluate this hypothesis with analysis on ensembles of three ResNet-18 models for which the Lipschitz constant is controlled by layer-wise clipping of the spectral norm for all the convolutional and dense layers using FastClip.
What we did
To promote the diversity of each pair of models (assuming identical architecture) with controlled Lipschitz continuity within the ensemble, we promote the orthogonality of each pair of corresponding layers from those models. To this end we introduced a new similarity measure to capture the alignment of top-k singular vectors for a pair of layers from the two models.
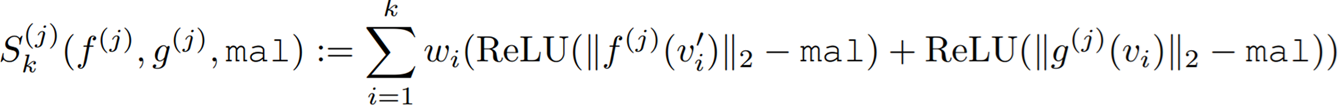
We then augment the loss value with this similarity value for each pair of corresponding layers for any pair of models in the ensemble.
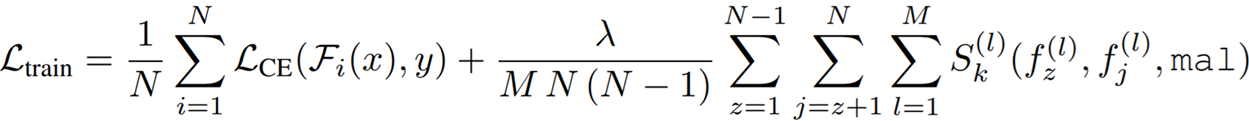
Results
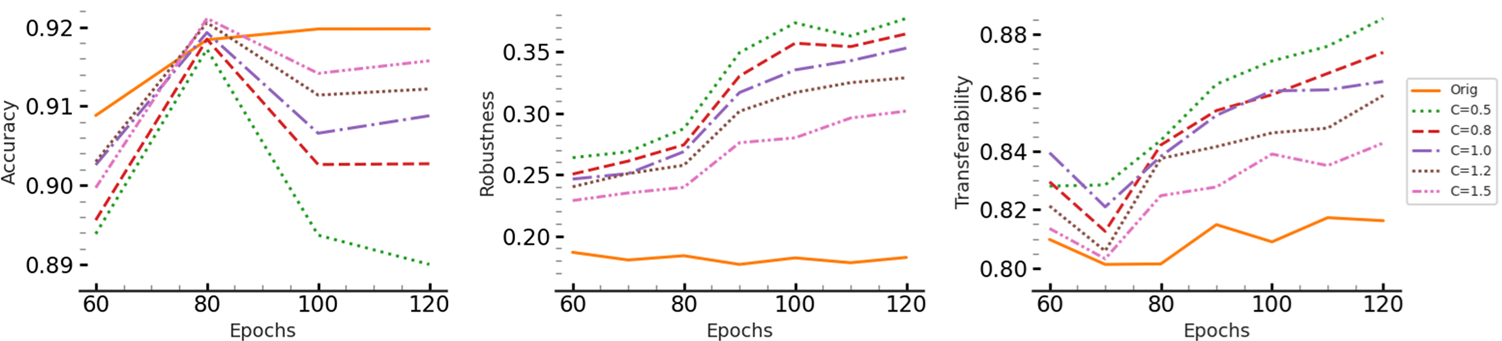
- Decreasing transferability rate. LOTOS Effectively decreases the transferability rate among pairs of models while benefiting from the controlled Lipschitz continuity of individual models.
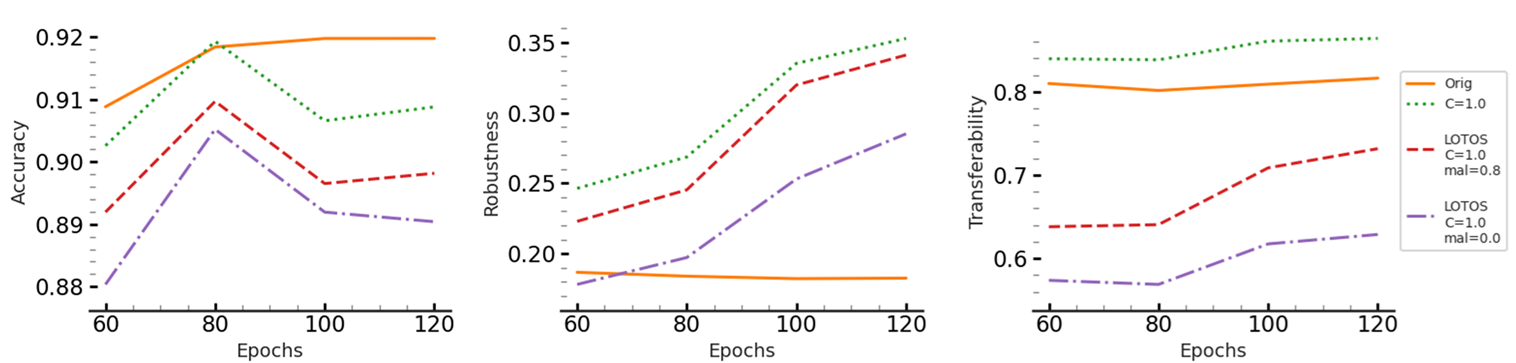
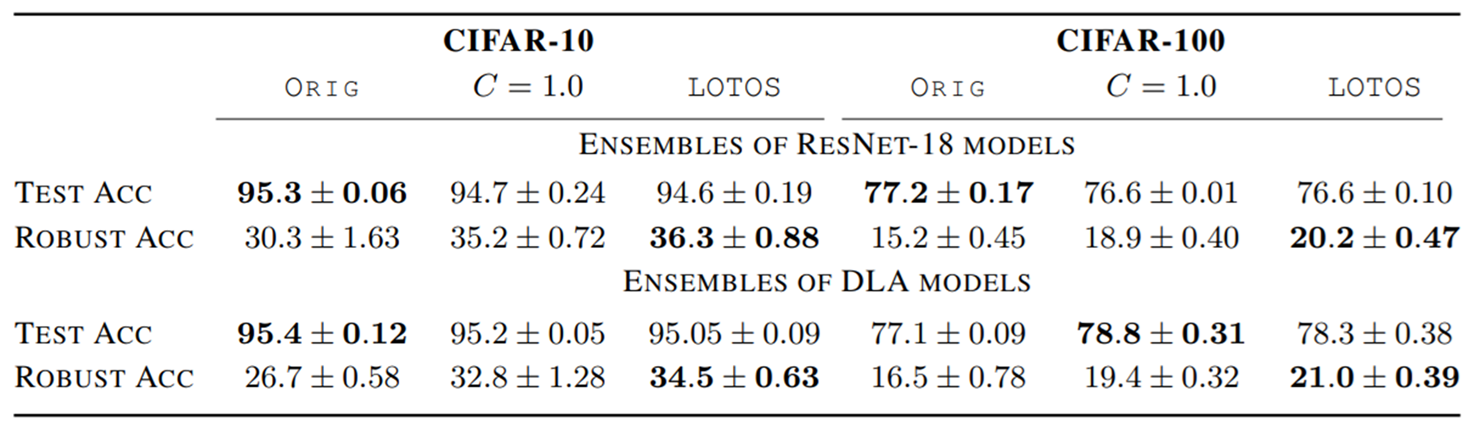
- More robust ensembles. LOTOS Effectively enhances the robust accuracy of ensembles of three ResNet-18 models trained on CIFAR-10.
- Heterogeneous ensembles. Unlike prior SOTA approaches (TRS and DVERGE), our method can also be applied to heterogeneous ensembles because the singular vectors of the first linear layer have the same dimension as the input images. So LOTOS can be applied to the first layers only in such ensembles.
Theoretical insights
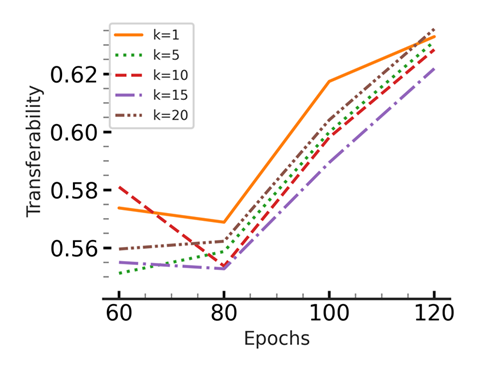
To increase the effectiveness we need to increase the value of k, but increasing the value of k increases the computational cost. We prove that for convolutional layers, even by considering only the largest singular vector (k=1), the other singular vectors are orthogonalized to some extent. Therefore, a value of k=1 is enough for model architectures containing convolutional layers.
Additional Results
We tested:
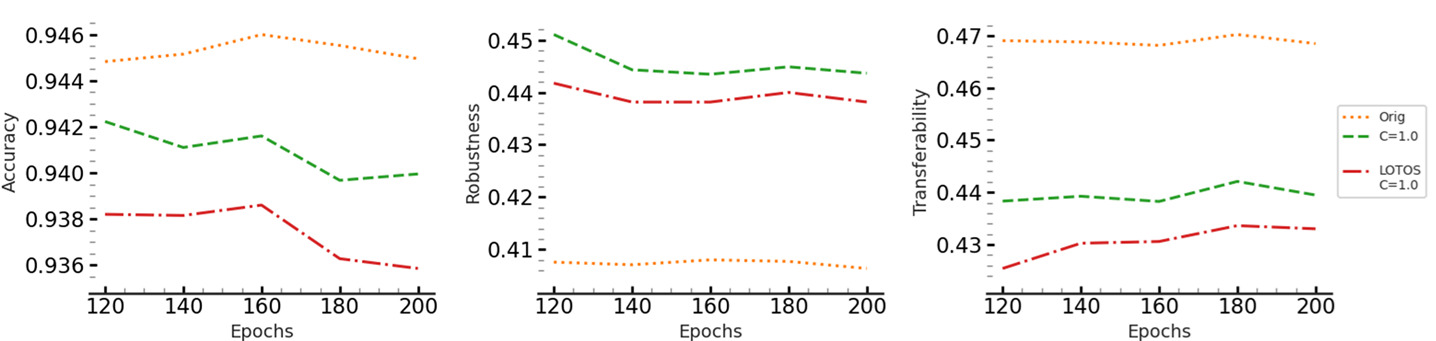
- Varying Ensemble Sizes: Larger ensembles benefit more from our method, but even small ensembles show consistent gains.
- Architecture Variants: The method works across ResNet-18, ResNet-34, and DLA.
- Different Datasets: Improvements are consistent from CIFAR-10 to CIFAR-100.
- Effect of k: Slight improvement by increasing k, up to a point, after which the results degrades (matching with our theoretical results).
- Combining with other methods: Combining our method with prior works, such as DLA, improves the robustness compared to using each method individually.