Latent Behavior Models
Latent models posit that user actions are reflections of their underlying preferences. How well can we predict these preferences to better serve users on online platforms?
Latent behavior models are critical to any application that requires us to make inferences about users online. A few prominent applications are product and service recommendation, activity prediction, user profiling, and understanding online communities, both implicit (i.e., by their observed similarities) and explicit (e.g., social networks). In the presence of dynamic, multi-faceted observations of users (facets are data modalities such as clicks, social relations, video playbacks etc.), the sparsity problem is exacerbated by the large resultant space of activity. Further, no one view of users is sufficient. We need to consider different subsets of the available behavioral facets for different applications. While a pre-determined set of data facets could leverage domain knowledge to address sparsity (e.g., how are clicked images linked to specific videos), it does not generalize to applications with other behavior facets or different prediction objectives.
Historically, a wide range of clustering methods were proposed to tackle these challenges (e.g., social regularization, cross-domain transfer and using external data to smooth sparse user data). The reasoning is fairly straightforward, regularizing user activity by clustering them with similar peers would bridge gaps in their own records. The key challenge is thus to identify coherent groups of users at an appropriate resolution to learn a group profile describing the constituent users, so as to address the sparsity challenge while still maintaining consistency within each group. Large coarse groups would be detrimental to the informativeness of the group profile and the quality of user inference, while tiny groups would lack user data to learn a group profile.
Clustering the Long-Tail
What are the implications of the so-called long-tail on clustering users online?
Long-tailed distributions are a fundamental characteristic of human activity, owing to the bursty nature of human attention. As a result, skew is often observed in any data facets collected from or involving human interaction. Consider the popular community Q&A forums, Stack-Exchanges. Clearly, the tail topics that require specialized or uncommon knowledge have a smaller number of followers, and even fewer active authors. This has a strong impact on content recommendation models for these users, they are effective on those who follow popular topics while proving ineffective on those with more uncommon interests. Clustering models often lump these long-tail users into aggregate clusters with popular users. This results in uninformative profiles, and coarse inferences that are not personalized to each user in the cluster.
In fact, adopting any specific parametric form to cluster these users is hard as well – the degree of skew may significantly vary from facet to facet, application to application, dataset to dataset. Even robust generative models that can extract underlying groups from data, such as LDA, implicitly assume that the discovered latent groups are similarly sized.
It is easy to see that skew and sparsity are intimately linked – Identifying more informative groups in the presence of skew helps us do a better job bridging the lack of data for individual users, while the reverse is also true, better inference for sparse users would help us create more coherent groups to begin with.
In summary, here are the key unanswered challenges to building descriptive user profiles online:
- Avoiding static parametrization – Since it is hard to account for the distributional properties of different combinations of facets that varied applications require us to model
- Making no implicit assumptions – For instance, LDA based models (a popular thread in behavior modeling) incorporate priors that are unsuited to model skewed data facets
- Beyond static facet modeling – Facet interactions can be modeled in many ways, and the combinatorial space expands rapidly. Thus, our frameworks to address skew and sparsity must be malleable.
In our paper at CIKM 2018, we proposed a flexible data-driven solution to address these challenges across diverse behavior modeling applications.
A Data-Driven Framework
Our approach is motivated by two key insights – First, a small fraction of users produce most of the data, while most others have sparse interaction histories, and second, in any behavioral data facet of choice such as the topic or tags in a Stack Exchange website, we observe varying degrees of skew.
The Restaurant Analogy: A useful analogy to think of in the context of user clustering is one of seating users in a restaurant. Users’ topics of interests can be thought of as dishes served on tables, so that users who like the same dishes are likely to sit together. Further, users could be moved across tables if required, and some tables are larger than others.
To continue the above analogy, we propose a user seating mechanism that is simultaneously skew aware by encouraging exploration to find the best tables for users, and deals with sparse users by seating them in the most coherent groups based on their limited observational data. We reiterate the interdependent nature of these two challenges – bridging gaps in the user data requires us to build coherent behavioral groups in the presence of skew, and vice-versa.
Pitman-Yor Process (PYP): We begin by visiting the non-parametric probabilistic Pitman-Yor process, also referred as the Chinese Restaurant Process (CRP) owing to the convenient customer seating analogy. The key-idea is to induce a power-law distribution in the seating arrangement for new users by preferring tables with many other users. In this sense, PYP is completely agnostic to the actual user, it only cares about the aggregate counts of users on tables. However, this is a good starting point for us to build our framework.



How do we leverage the explorative nature of the Pitman-Yor seating process to improve group coherence and address skewed profiles?
First, behavioral groups cannot be agnostic of the individual profiles of users. To continue the CRP analogy, the dishes served on each table can be viewed as the profile describing the seated users. Users are more likely to sit on tables serving dishes they like (i.e., profiles best describing their activity traces) so that the resulting groups tend to cluster similar users. But how do we prevent all users being assigned to the same profile, which is a possibility in a rich-get-richer process? We must encourage exploration to find distinctive user profiles on the facets that we are modeling, without any rigid assumptions on the extent of observed skew. Conversely, to prevent too many profiles, we will place an upper bound on the number of profiles and permit a profile to be drawn on more than one table. We now introduce our formulation:

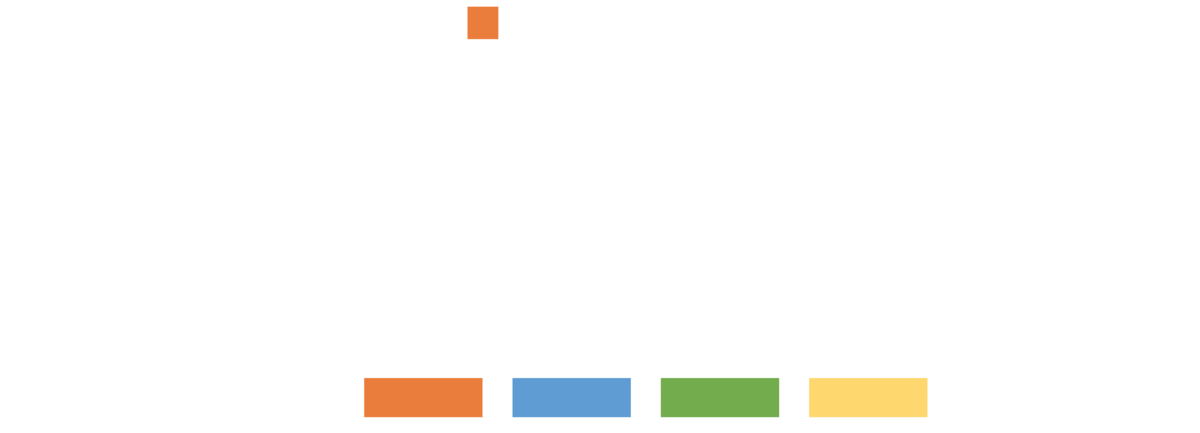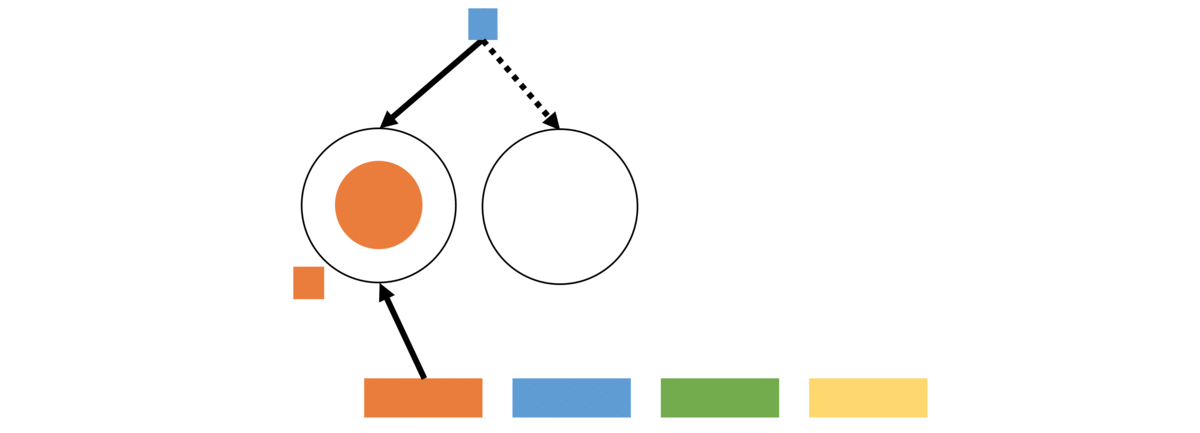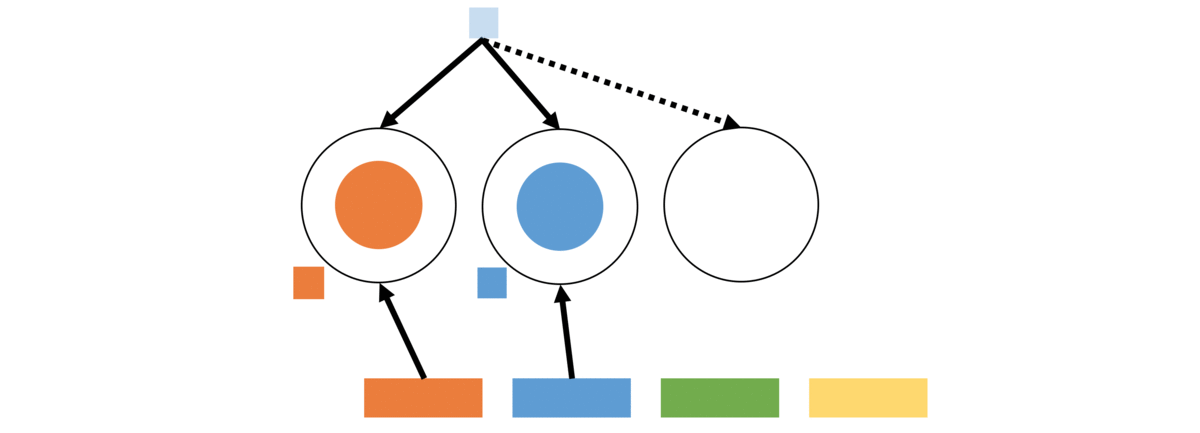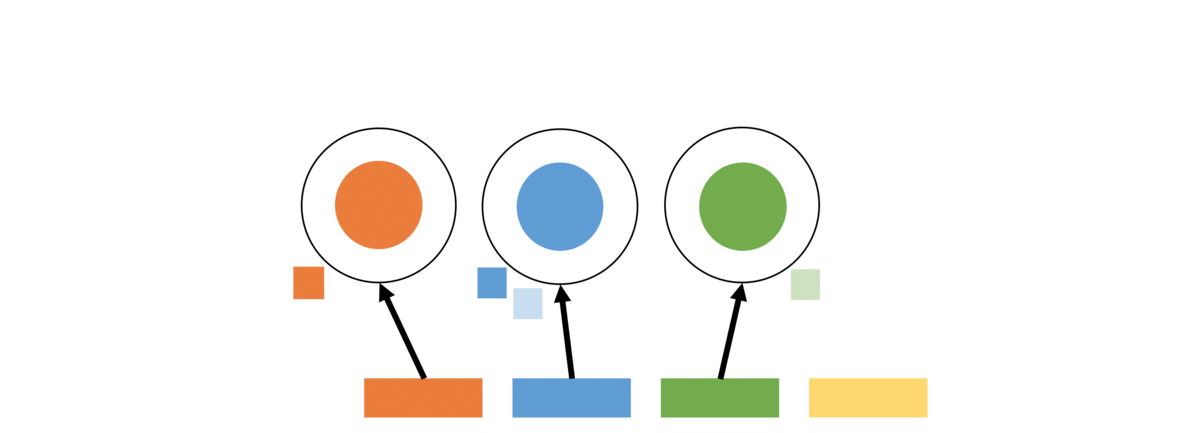
Now let us consider the effect of the above seating arrangement. Specifically, consider the likelihood of assigning a specific profile to a user. This can happen in two ways – the user could be seated on a table serving that profile or be seated on a new table and draw that profile on the new table. Let us consider the summed likelihood of these two possibilities for a user.

The most common profiles are likely to be drawn on many new tables as they are created. As a result, the discount term in the above equation significantly penalizes common profiles thus encouraging exploration and potentially discovering new profiles that vary from the existing ones. The more tables a profile is drawn on, the greater the discount effect – this prevents the case where we end up with uninformative generic profiles on too many tables. The discount parameter controls the extent of exploration – a larger value magnifies the discounting effect.
Significance and Findings
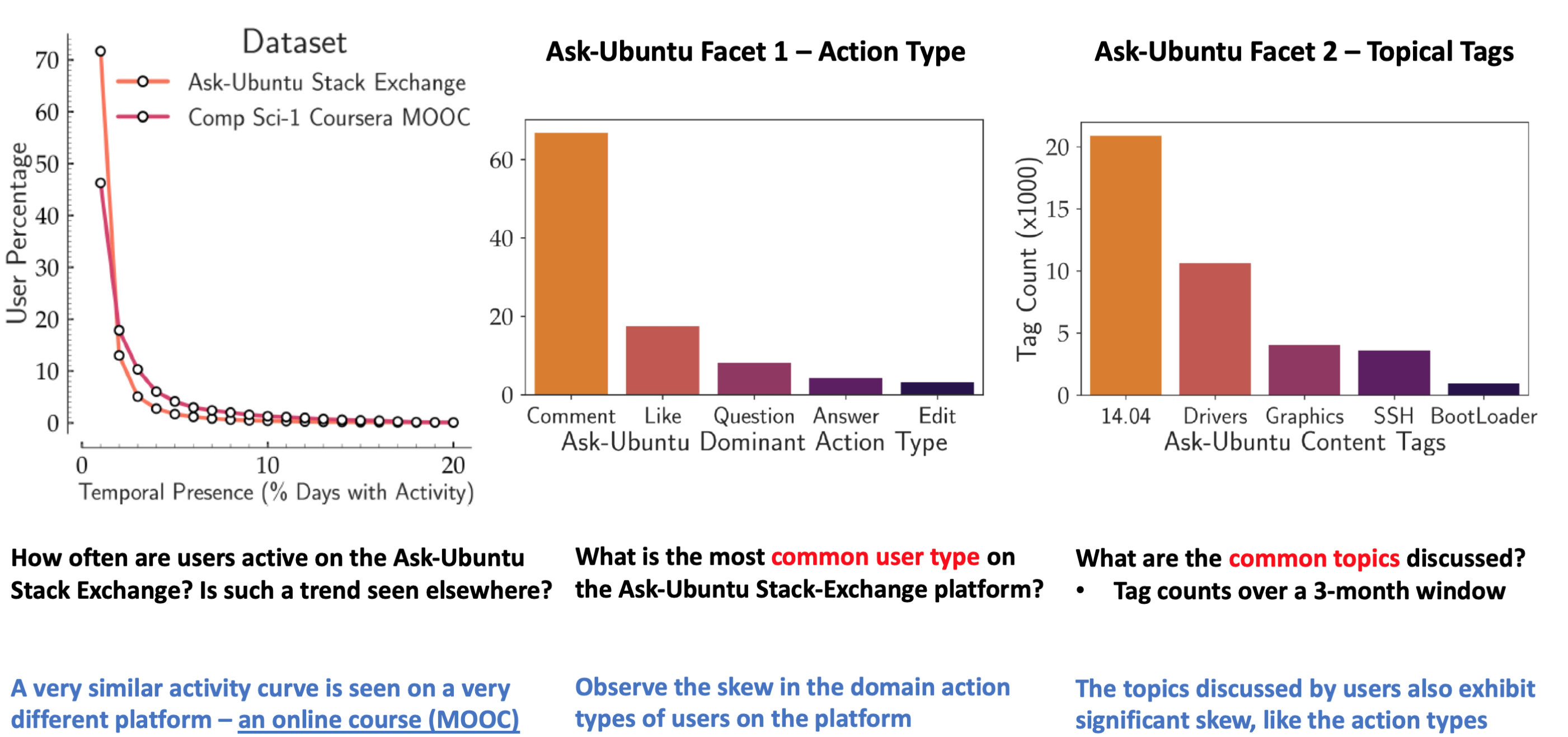
We now compare the user clusters obtained with our seating arrangement with those from BLDA, an LDA-based behavior model on the Ask-Ubuntu Stack-Exchange. Both models group users best described by the same profile to form clusters. We use the average user reputation score in each cluster (appropriately normalized) as an external validation metric for cluster quality.
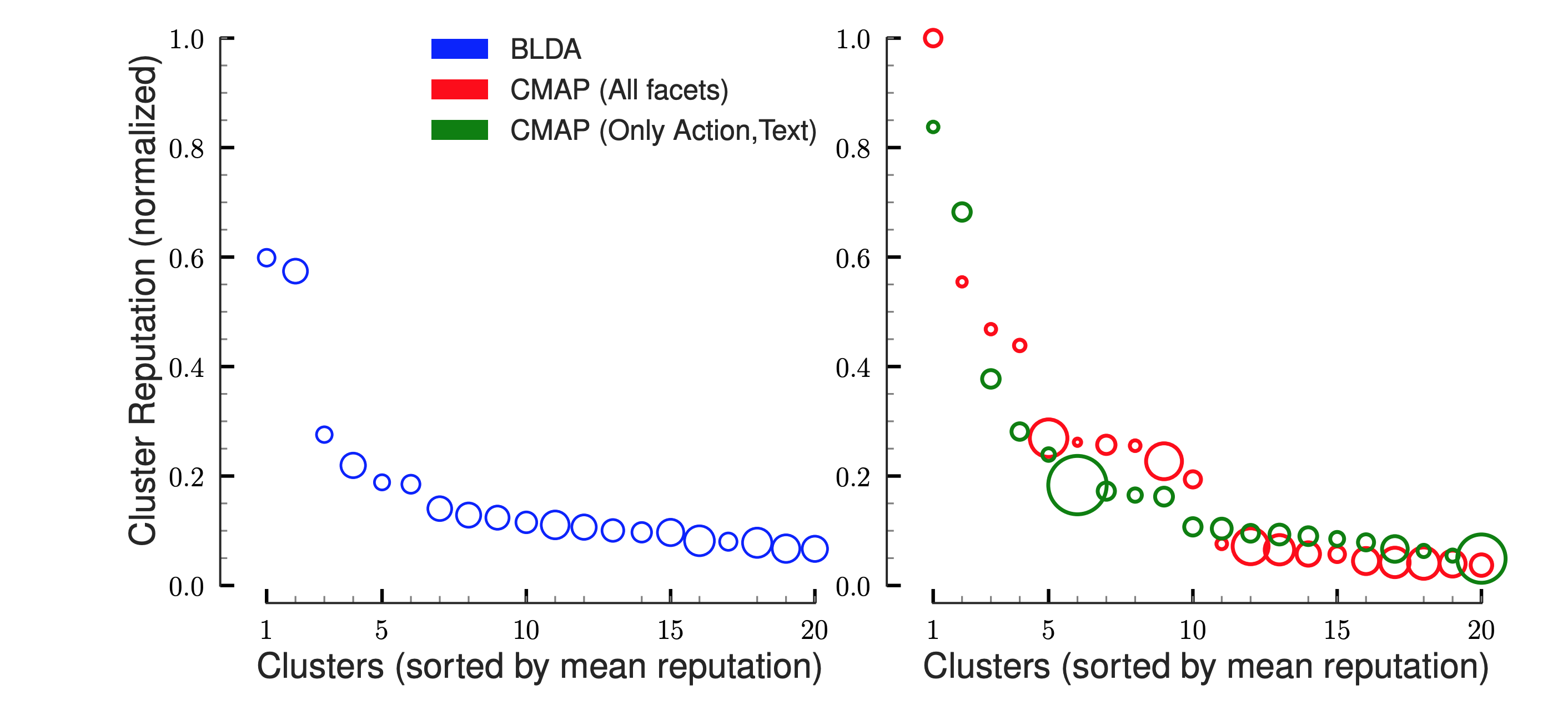
BLDA tends to merge profiles and hence shift cluster sizes and average participant reputation closer to the mean. Our cluster assignments reflect finer variations in the topic affinities and actions of expert users. The top three profiles are more reputed, smaller in sizes and each cluster shows distinctive user activity.
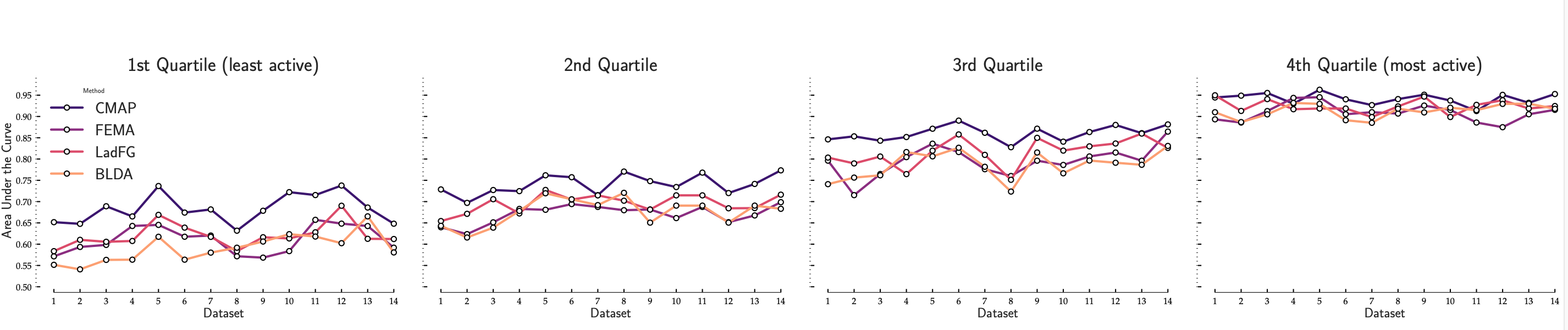
To evaluate for sparsity mitigation, we split users across several Stack-Exchange and Coursera MOOC datasets into four quartiles based on their interaction counts (Quartile 1 is least active, Quartile 4 is most). Then, we evaluate each method on the Reputation Prediction task AUC in each quartile separately. Clearly, our model shows significant performance gains in the sparse quartiles. We attribute these gains to joint profile learning to describe similar users seated on tables.
tl;dr
In summary, the decision to address skew and sparsity jointly has two advantages: better profile fits for sparse users and more distinct and informative profiles in skewed scenarios. In contrast, models building representations at the user level perform weaker in the long-tail (Quartiles-1,2) since they rely on per-user interaction volume for inference. As expected, performance differences between all models are smaller among the data-rich users (Quartiles 3,4).
Useful Links
You can learn more about our work by reading our paper on the ACM Digital Library or an older version on arxiv. A C++ implementation is publicly available on Github.
@inproceedings{krishnan2018insights,
title={Insights from the long-tail: Learning latent representations of online user behavior in the presence of skew and sparsity},
author={Krishnan, Adit and Sharma, Ashish and Sundaram, Hari},
booktitle={Proceedings of the 27th ACM International Conference on Information and Knowledge Management},
pages={297--306},
year={2018}
}