Deep Neural Recommenders and Data Sparsity
Deep recommendation models often learn both, user and item embeddings, and transformation layers in a joint ranking function. Can we reuse or share these learned layers across multiple recommender applications?
Although deep neural recommenders outperform conventional methods by wide margins in aggregate ranking metrics, sparsity, or the long tail of user interaction, remains a central challenge to personalized recommendation. A simple questions that follows is: How do we reuse or transfer high-performant recommendation models to benefit domains, applications, users and items that lack high-quality training samples (i.e., enhance the sample efficiency) ?
In the below plot, we investigate the ranking performance metric for two diverse state-of-the-art neural recommenders, one with a deterministic feed-forward architecture (Collaborative Denoising Autoencoder or CDAE), and the other with a stochastic deep generative architecture (Variational Autoencoder or VAE).
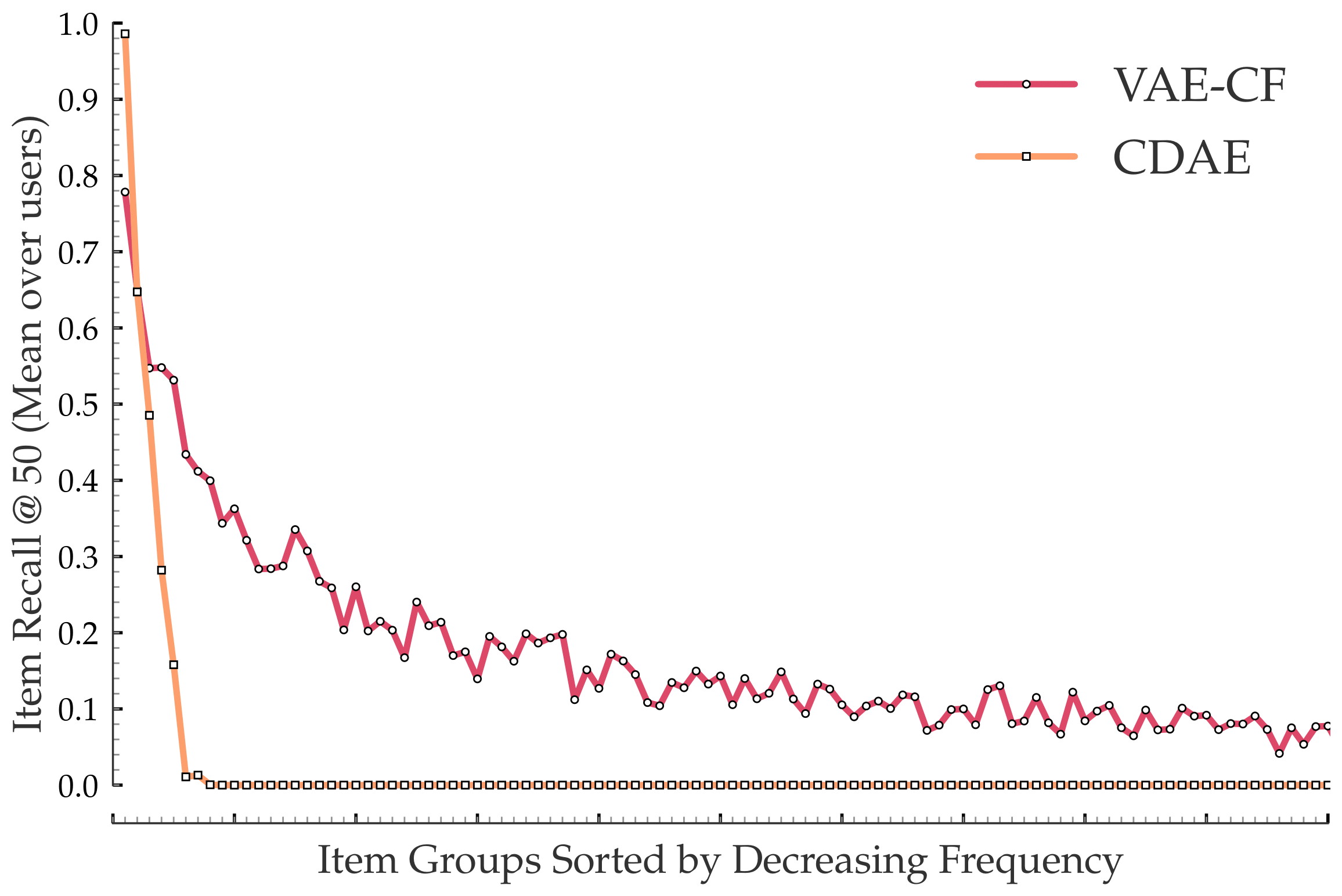
Sparsity challenges exacerbate generalization and overfitting challenges with deep recommenders. There are two key inferences from the above study:
-
On sparsity and imbalanced training data - A skewed distribution of training data results in us learning a biased recommendation model that only recommends the popular subset of the item inventory.
-
Applications, Users, Items - Data sparsity occurs at multiple granularities, not just for individual users or items in a given recommender application. In this post, we address the broadest setting where an entire recommender application lacks user-item training data. Our solution trivially extends to the narrower problem of sparse users and items in a single application by splitting them across two recommendation models.
Transferrable Neural Recommendation
Transferrable neural recommenders simultaneously address two challenges - Sparsity and distributional challenges in the training data (Sample efficiency), as well as the computational costs of training separate deep recommender models (Computational efficiency).
Cross-domain transfer learning is a well-studied paradigm to address sparsity in recommendation. The first class of prior art assumes that users or items are shared across the two domains or applications.
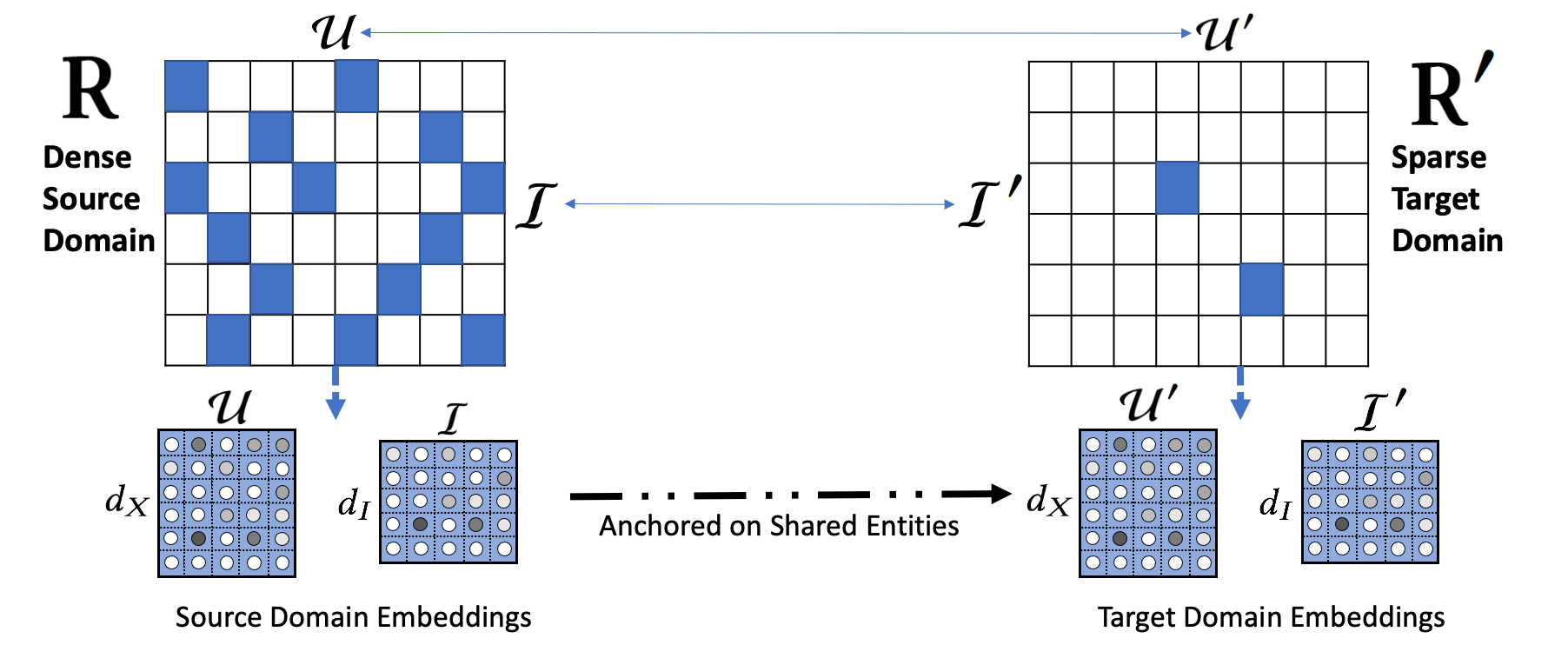
The second setting does not assume any overlap, however imposing more restrictive structural alignment in the user and item representations across the two domains.
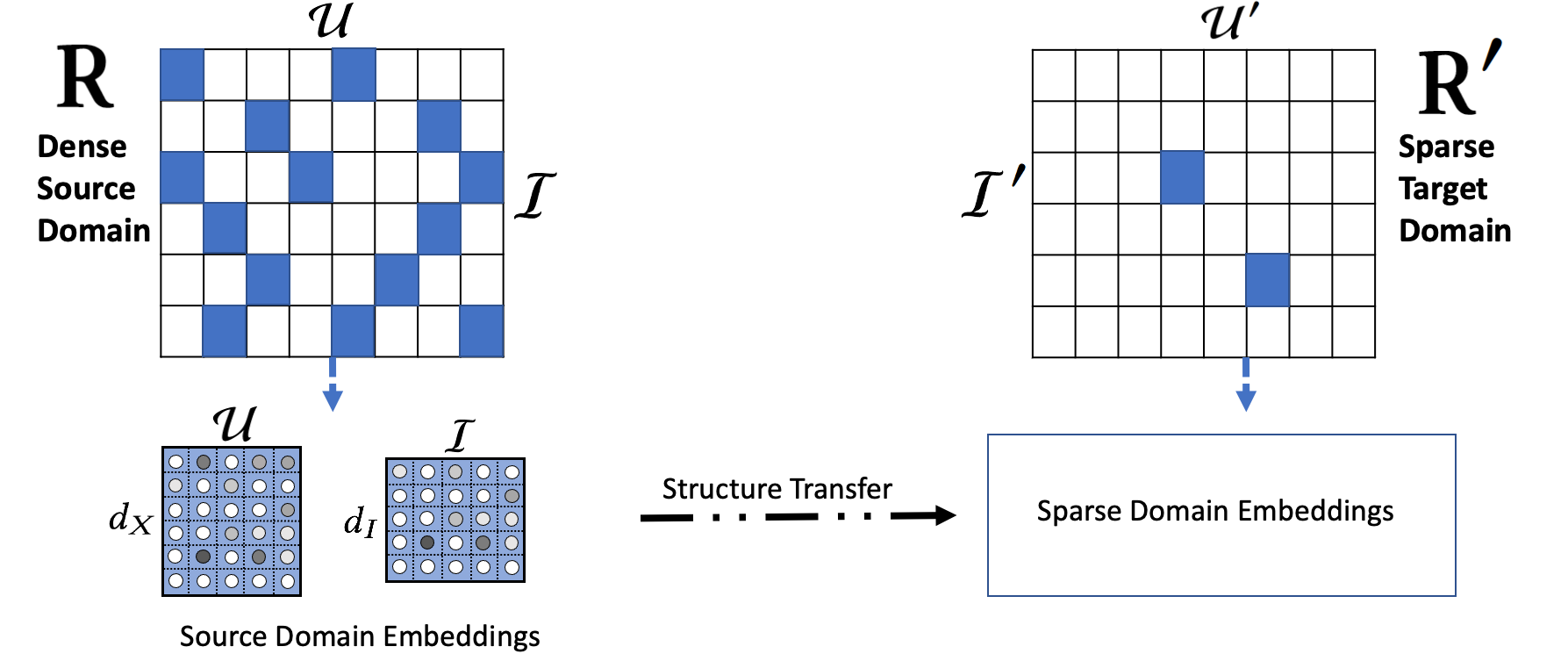
We note that recommendation domains with limited user-item overlap are pervasive in real-world applications, such as geographic regions with disparities in data quality and volume (e.g., restaurant recommendation in cities vs. sparse towns). Historically, there is limited work towards such a few-dense-source, multiple-sparse-target setting. Our problem setting represents this challenging scenario for cross-domain transfer learning.
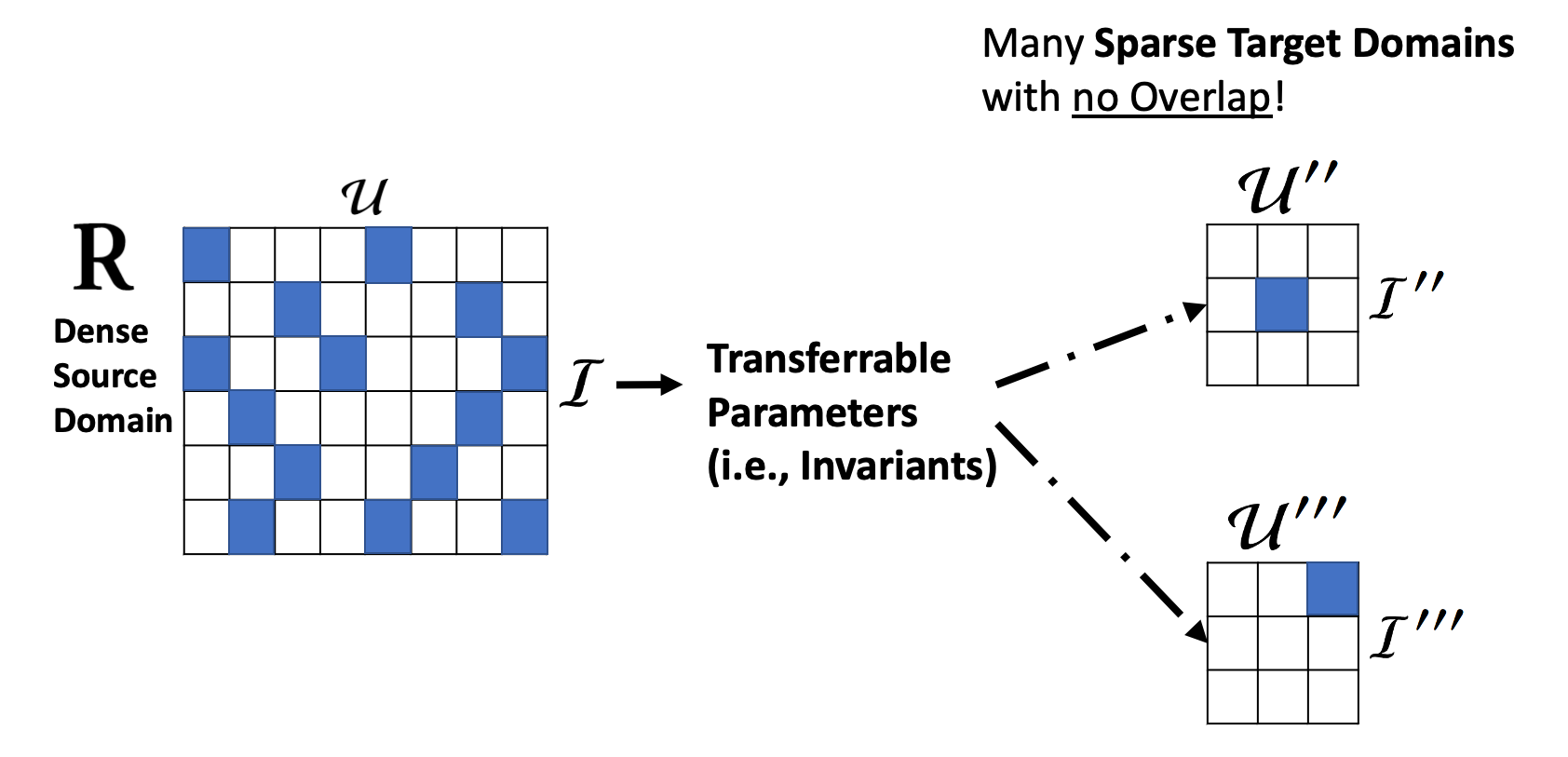
We propose to solve this multi-domain transfer-learning problem with a scalable parameter sharing solution - Extract a single set of transferrable parameters (i.e., invariants) from the source domain, and reuse these parameters across all the target domains to maximize reuse.
Our Key Insight
Contextual features of user-item interaction provide insights to user-intent and item-utility. We can leverage these behavioral insights to improve user and item inferences with fewer training samples.
Context-aware recommendation has become an effective alternative to traditional methods owing to the extensive multi-modal feedback from online users. Combinations of contextual predicates are critical in learning-to-organize the user and item latent spaces in recommendation settings.
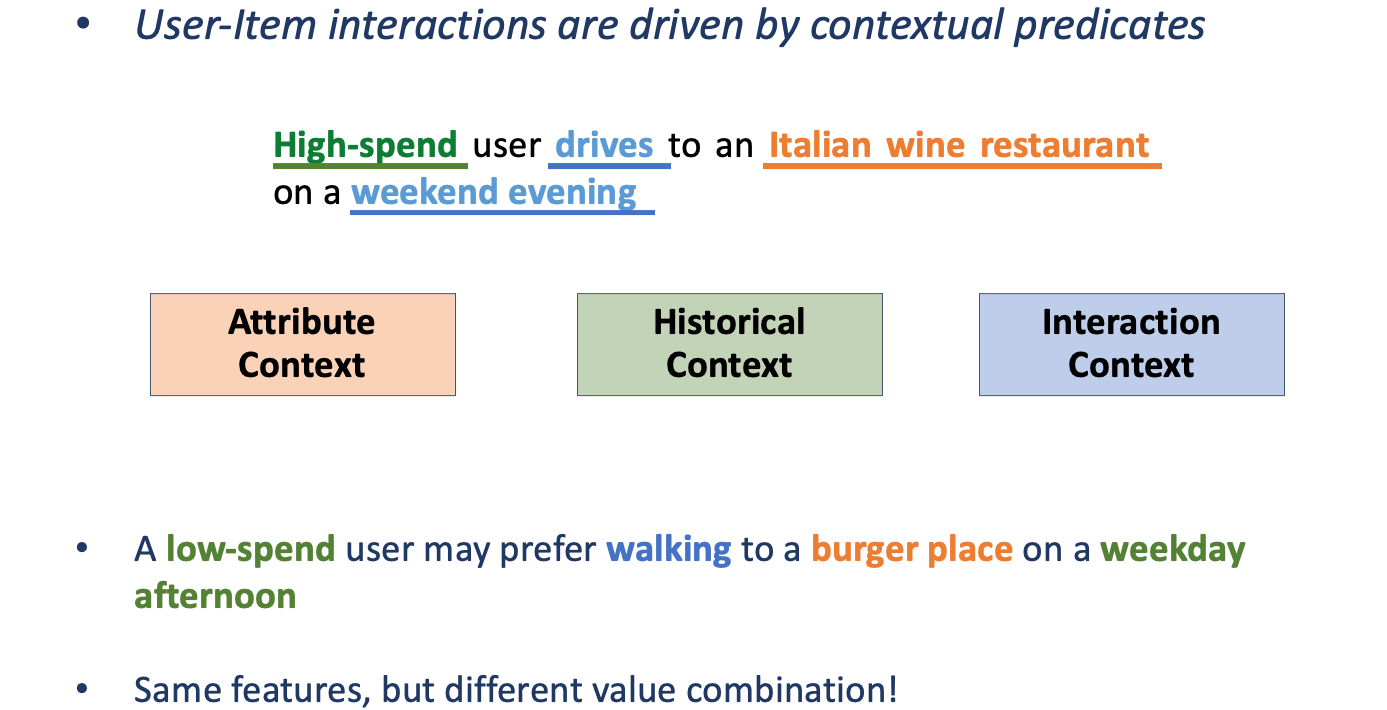
Our key insight is as follows - The likelihood of a user-item interaction can be described by three components:
-
User and Item Embeddings (Not transferrable) - These embeddings capture the eccentricities of individual users and items
-
Context combinations (Transferrable) - The above example exhibits a specific combination - spending pattern, cuisine and time of visit for a restaurant recommendation problem. We extract multiple such combinations with associated weights, and cluster users by their preferences along these contextual combinations. These cluster structures and combinations are transferrable across users and similar applications.
-
Joint scoring/ranking function (Transferrable) - The joint scoring function combines the domain-specific, non-transferrable user and item embeddings with the transferrable context combinations to produce an overall likelihood of an interaction.
In our paper at SIGIR 2020, we proposed a modular architectural framework, and a choice of training algorithms to facilitate the learning of the above three components on a data-rich source domain, and subsequently transfer it to a data-sparse target domain to improve the representation learning in the sparse domain.
Modular Transfer Framework
We achieve context-guided embedding learning three synchronized neural modules with complementary semantic objectives:
-
User and item embedding module (Not transferrable) - Stores or computes the non-transferrable individual embedding representations of users and items. We do not make any assumptions on the architectural choices, however the output of this module is a d-dimensional pair of embedding vectors for an interacting user and item.
-
Context module (Transferrable) - The context module complements the user and item embeddings by extracting the most important context feature combinations from each interaction.
-
Clustering and ranking modules (Transferrable) - These layers combine the outputs of the above modules for each (user, context, item) interaction triple, and generate an overall likelihood score for the interaction.
The overall model architecture is detailed in the following architecture diagram,
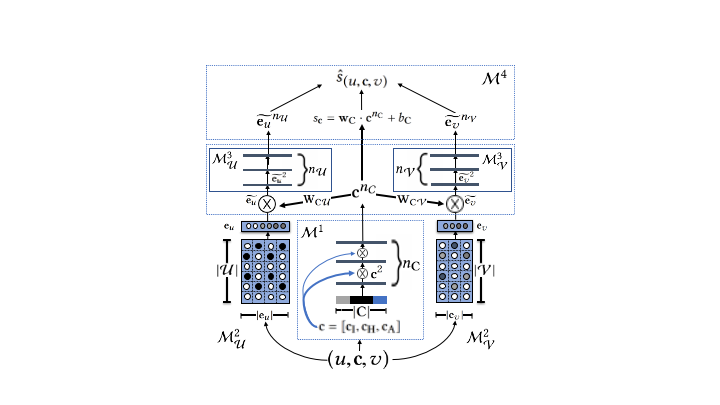
For more details on the training algorithm and architectural components, we request readers to refer our work.
Significance and Findings
Our overall findings and results can be summarized across two broad categories, sample efficiency, i.e., leveraging our transferrable architecture to benefit sparse applications with limited training data, and computational efficiency by reusing and transferring pre-trained neural layers.
In terms of sample efficiency, our key findings are as follows:
-
Interaction context is an effective invariant to tackle sparsity at multiple granularities, for sparse users and items in a single recommender application, or across appplications and domains sharing similar contextual features and semantics.
-
The multi-linear formulation of contextual invariants is very important for transfer-learning, we show connections to Attentive Neural Factorization Machines (AFM) in our analysis, and show that our framework is a n-variate extension of the bivariate feature combinations in AFM.
-
We present detailed analyses on two public datasets, Google local merchant reviews, and Yelp restaurant reviews, in our experiments. Across both datasets, we split the user-item interactions by their geographic location and show transferrability between dense and sparse geographic regions.
In terms of computational efficiency, we obtain a 3x speedup in the training time when we employ our transfer techniques in comparison to training models from scratch:
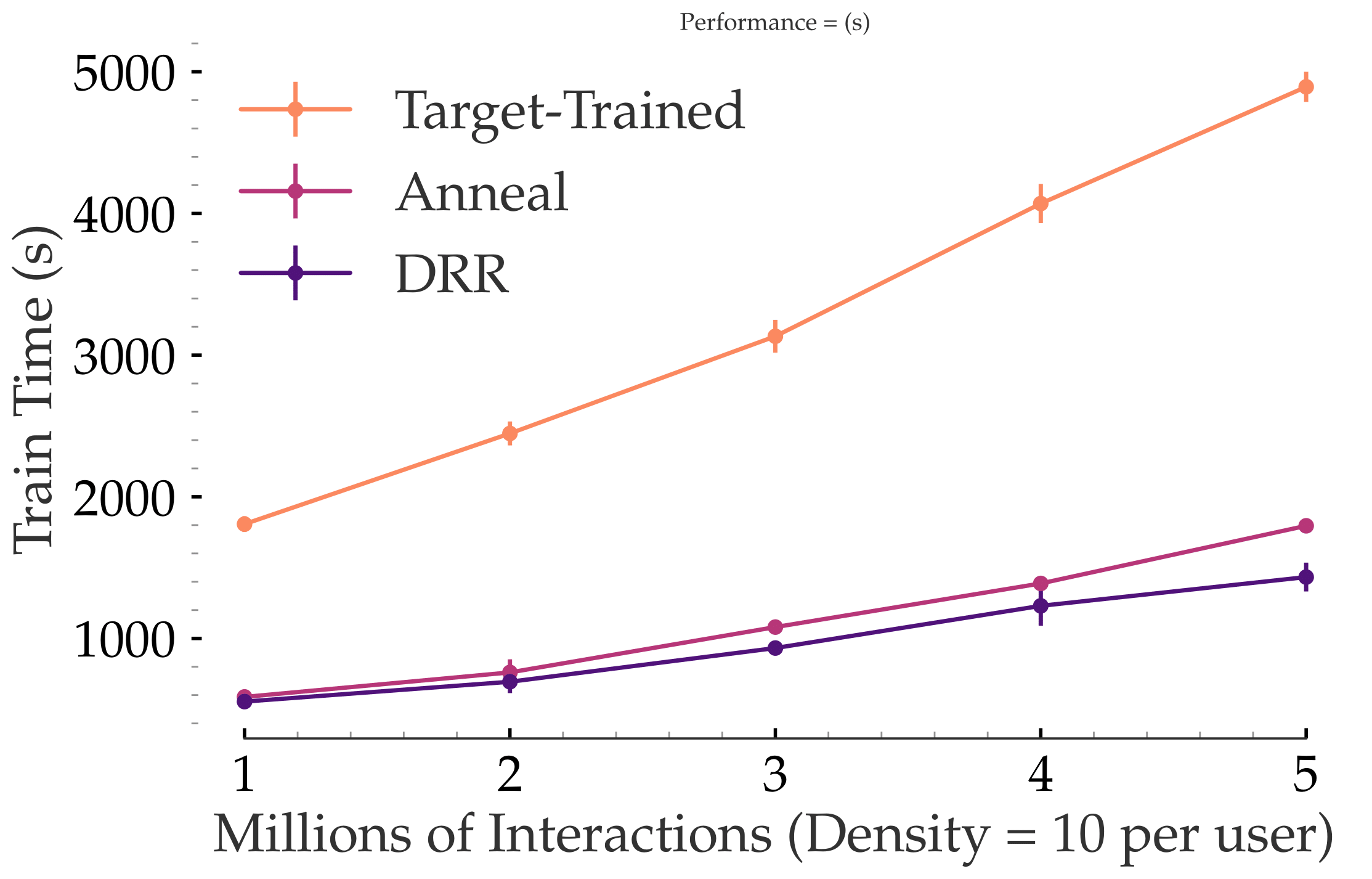
We developed simulated annealing and distributional residual learning techniques to transfer the trained model across applications. We find both approaches to significantly outperform and train faster than fitting new models from scratch.
tl;dr
In summary, our paper proposes a modular architecture to achieve transferrable neural recommendation across domains by extracting shared contextual invariants, and learning a combination of domain-specific and domain-independent components to work in tandem for optimal performance. Our approach is able to effectively mitigate sparsity by leveraging the learned contextual invariants, and significantly reduce computational effort by reusing learned neural components in the sparse domains or applications. We envision our work to spur the further development of context-driven meta-strategies towards reusable user behavior models.
Useful Links
You can learn more about our work by reading our paper on the ACM Digital Library or a PDF copy here.
@inproceedings{10.1145/3397271.3401078,
author = {Krishnan, Adit and Das, Mahashweta and Bendre, Mangesh and Yang, Hao and Sundaram, Hari},
title = {Transfer Learning via Contextual Invariants for One-to-Many Cross-Domain Recommendation},
year = {2020},
url = {https://doi.org/10.1145/3397271.3401078},
doi = {10.1145/3397271.3401078},
booktitle = {Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval},
series = {SIGIR '20}
}