In a nutshell
Have you experienced frustration while browsing your personalized recommendations on Netflix and then turned to watch a movie that is trending instead? The trending title that you watched was probably ok, but perhaps not exactly what you were in the mood for. Your sense of disappointment is justified—after all, with hundreds of millions of customers, decades of historical data, and the use of sophisticated AI algorithms, why does this happen? At a high-level, movie recommendation algorithms work by finding other users with similar viewership and rating history as you. Then, they recommend movies that these other users have liked. But clearly, this doesn’t always work as planned. Let’s examine why.
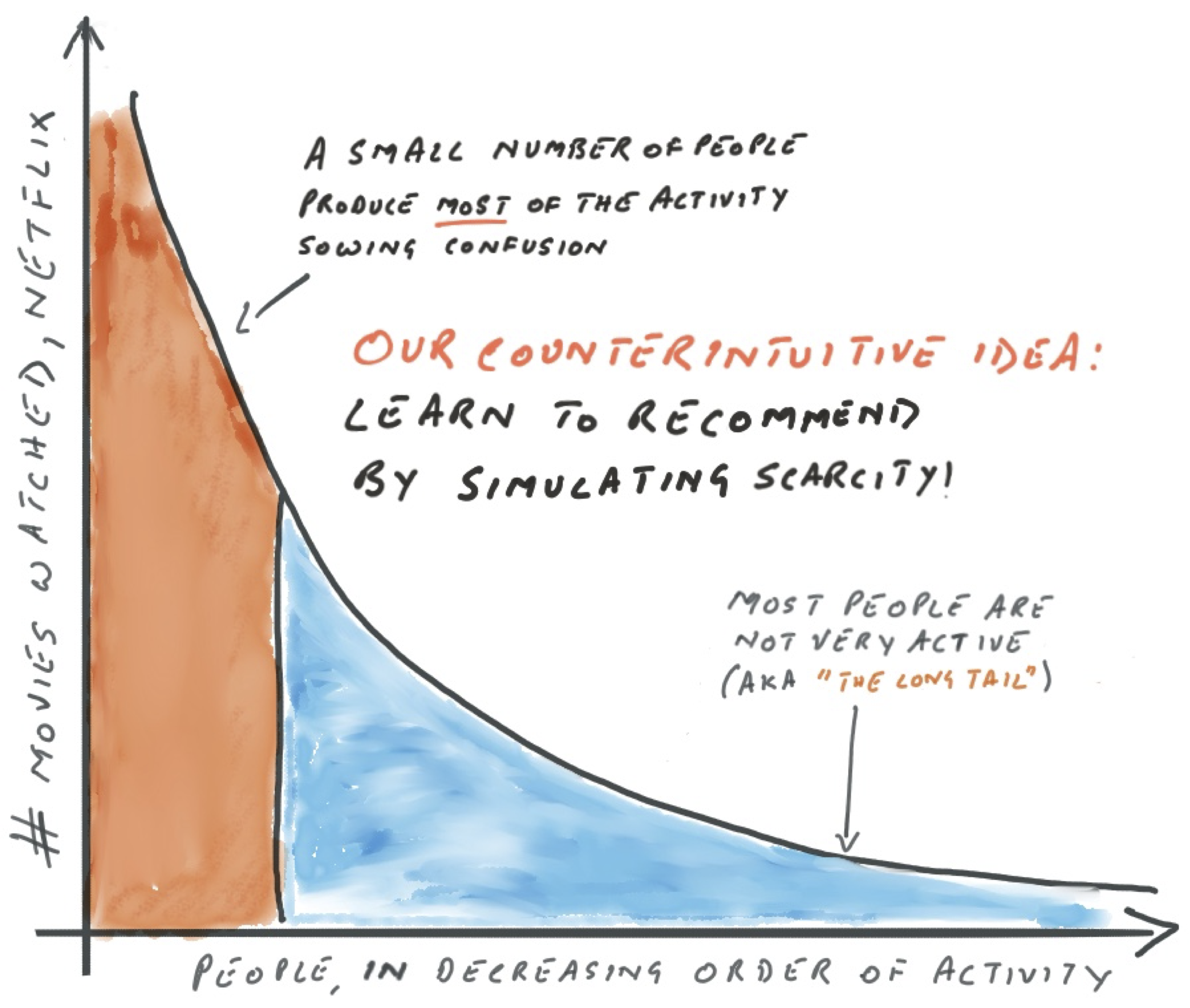
The unequal distribution of human activity and what sophisticated AI algorithms do with this data are responsible for poor personalized recommendations. A fascinating aspect of human-generated data (like our ratings) is that a fraction of the population generates most of the rating data! Furthermore, most movies don’t have ratings. With scarce movie ratings, even the most sophisticated algorithms today make their recommendations by paying attention to the most active movie watchers or movies with the most ratings.
We have a clever counterintuitive idea to this wicked problem of rating scarcity: what if we treated all movies as equally bereft of ratings? This change in perspective dramatically improves the quality of the recommendations over the best-known ones. We learn to recommend new items by learning the underlying geometry of the items of this sparse dataset. We can learn the underlying geometry despite the lack of data. We deem two items similar if they are similarly distant to item landmarks (e.g., cluster centroids) discovered by a base recommender trained on the whole dataset.
Our work will impact all e-commerce platforms that rely on human activity to make recommendations. Moreover, we’ve made it future-proof. The problem of getting personalized recommendations right is not limited to Netflix. The problem occurs on all e-commerce platforms that rely on past human behavior (e.g., Amazon) to make recommendations. We’ve known for over a century (known as the Pareto principle) that a small number of people account for the bulk of the human activity. The Pareto principle means that you can’t fix the problem of poor personalized recommendations by getting more people to sign up or wishing for a better algorithm. The highly unequal distribution of human activity is a fundamental challenge.
We recognize that advances in AI will render any current solution irrelevant quickly. We have chosen to future-proof our framework by ensuring that it works with any base algorithm that makes recommendations. The challenge with Deep Neural models isn’t that they aren’t capable enough, but that they need a framework that guides them to pay attention to the diversity of human activity.
Details (because they matter!)
Popularity Bias in Collaborative Filtering
While the overall ranking accuracy of neural recommenders is high, accuracy levels are poor for most items in the heavy tail of the inventory.
Deep neural networks form the backbone of modern recommender systems in popular e-commerce (e.g., Amazon), content streaming (e.g., Netflix), and social networking platforms (e.g., Facebook). Neural recommenders outperform conventional methods by large margins in aggregate ranking metrics (NDCG and Recall); however, most users do not receive recommendations aligned to their specific tastes but are instead suggested popular items in the inventory.
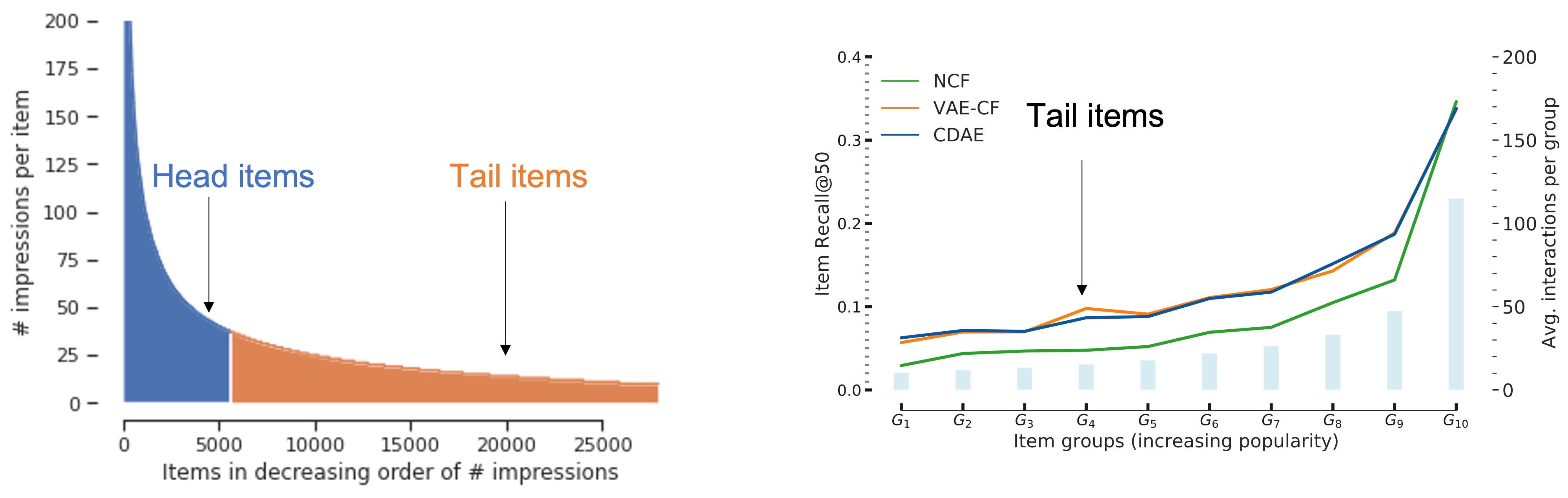
The fundamental challenge of popularity bias stems from the heavy-tailed distributions of user interests and consumption patterns in online interactions, i.e., much of the observed activity is due to a small fraction of users/items. Figure 1 empirically compares three popular neural recommenders (NCF, VAE-CF, CDAE) for different item groups ordered by increasing popularity. Due to severe interaction sparsity, prior neural recommenders lack the resolution power to rank long-tail items accurately.
Prior work has addressed the long-tail challenge via data re-sampling, model regularization, and the use of side information (e.g., attributes, knowledge graphs). We overcome the limitations of static sampling and regularization strategies by designing a generalizable framework that complements architectural advances in neural recommenders and enables flexible adaptation to the tail.
Few-shot Recommendation
How can we learn to recommend items with few interactions? Simulate the distribution of data-poor tail items during model training by sub-sampling interactions from data-rich head items.
Despite the enormous potential of neural models in learning subtle behavioral patterns from massive interaction logs, their long-tail performance is subpar. The skewed interaction distribution used for model training results in a biased recommendation model that only recommends the popular subset of the item inventory, which suggests the following question: can we develop a training strategy to eliminate the distribution inconsistency between head and tail items?
Meta-Learning (learning-to-learn) is a well-studied paradigm for few-shot learning tasks to rapidly learn to classify objects given only a few training examples. The meta-learner gains experience from a collection of carefully constructed meta-training problems, which enables generalization to new tasks. Prior frameworks typically consider meta-learning over a handful of classes. In contrast, the online recommendation setting poses a new and interesting challenge due to the massive scale of item inventories.
We formulate a few-shot learning-to-recommend problem for tail items to exploit the experience gained from data-rich head items. In a $k$-shot recommendation problem, the goal is to generate personalized recommendations given (up to) $k$ interactions per item.
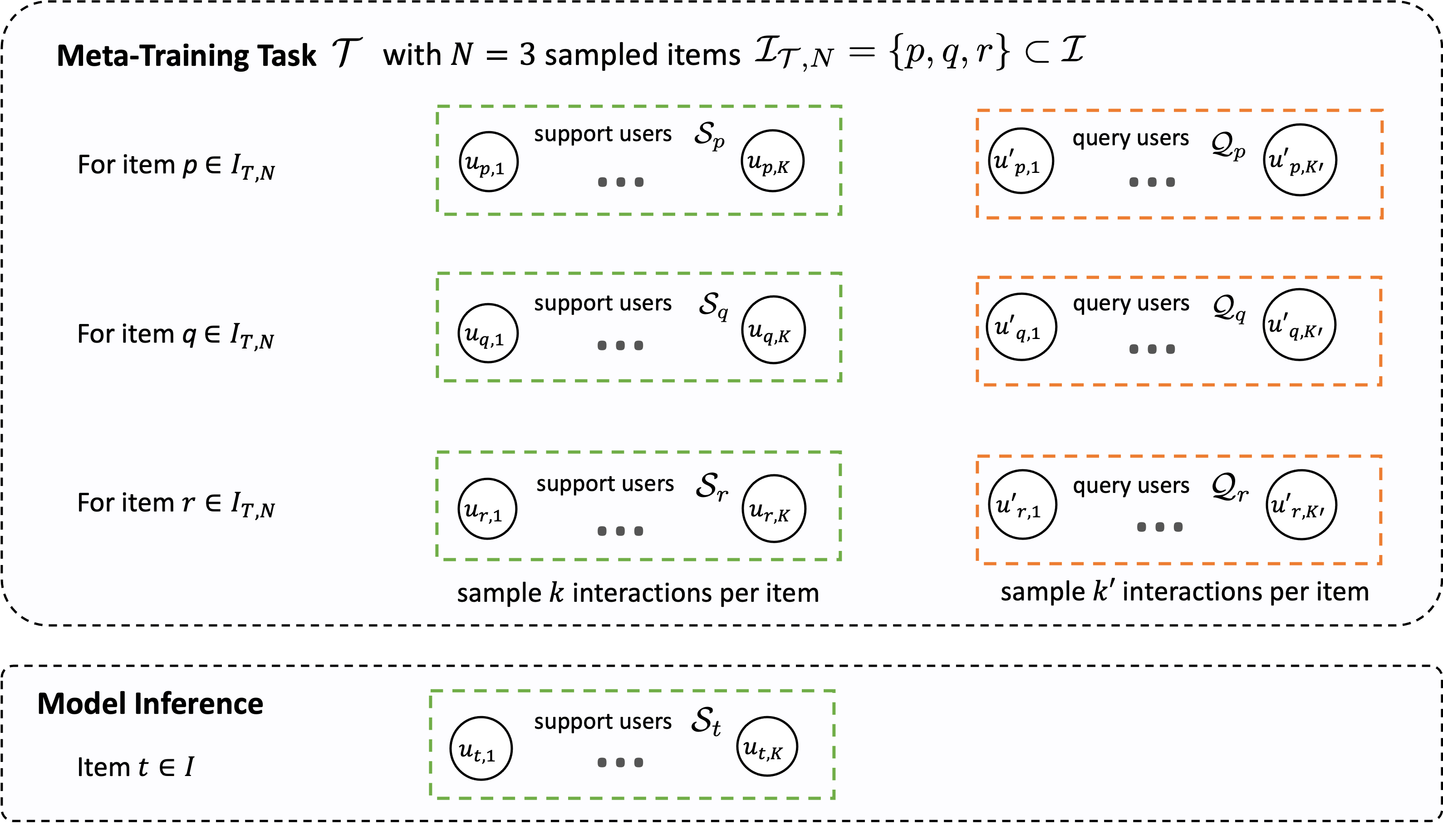
The few-shot recommender $R_F$ (or meta-learner) is trained over a collection of meta-training tasks that simulate $k$-shot recommendation (Figure 2) where $k\approx 5-10$. Each meta-training task $\mathcal{T}$ consists of support $S$ and query $Q$ user sets over $N$ items, which are analogous to training and testing sets. The meta-learner learns to recommend items based on $K$ sub-sampled support set interactions (per item) and receives feedback from $K’$ corresponding sub-sampled query set interactions.
ProtoCF: Prototypical Collaborative Filtering
We introduce a metric-based meta-learning framework ProtoCF for few-shot recommendations:
-
Metric-based Meta-learning: The few-shot recommender $R_F$ learns to embed items with few interactions. We learn a shared metric space of users and items where $R_F$ learns to construct an item prototype from its $K$ support interactions and recommends items by retrieving the nearest prototypes to each user.
We first compute an initial item prototype by averaging the $K$ user embeddings in the support set; however, simplistic averaging might lack the resolution to characterize the heterogeneous long tail. To learn discriminative item prototypes, we exploit knowledge from a pre-trained base recommender $R_B$. -
Head-Tail Knowledge Transfer: We design a knowledge transfer strategy that can effectively summarize the knowledge of item-item associations from the base recommender $R_B$ in the form of a set of group embeddings.
We can intuitively visualize the group embeddings as centroids of overlapping item clusters; conversely, items are learnable mixtures over the group embeddings. The initial prototype is enhanced by relating it to other relevant items through the group embeddings.

Finally, since $R_F$ is specifically tailored to the long-tail, we compute overall ranking scores by ensembling predictions from the few-shot $R_F$ and base $R_B$ recommenders. For more details on the training algorithm and architectural components, we request readers to check out the paper.
Significance and Findings
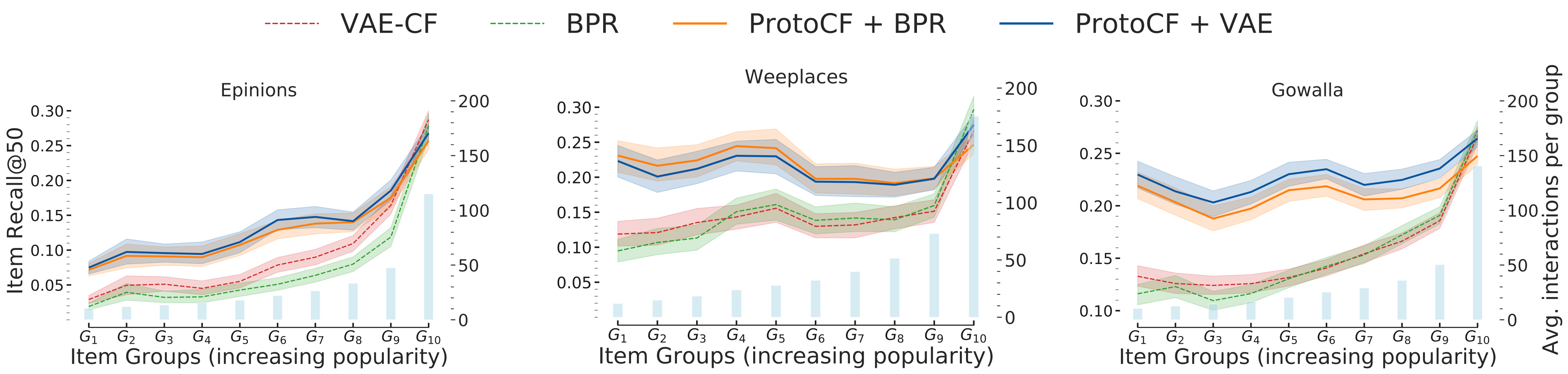
We instantiate our framework ProtoCF with two base recommenders: BPR (matrix factorization) and VAE-CF (variational auto-encoders). Here, we present detailed analyses on three public datasets, Epinions, Weeplaces, and Gowalla. Our key findings are as follows:
-
We observe significant performance improvements (over the corresponding base recommenders) on the tail items (item-groups G1 to G8) while maintaining comparable performance on the head items (item-groups G9 to G10).
-
The performance gains are especially significant on the Weeplaces and Gowalla datasets (location-based user check-ins), compared to Epinions (purchases in an e-commerce platform). Group embedding learning (as centroids of item clusters) is clearly effective at geographically clustering locations in Weeplaces and Gowalla. In e-commerce platforms (such as Epinions), it is worth exploring alternative knowledge summarization strategies (e.g., hierarchical item taxonomy or a product graph).
Resources
You can learn more about our work by reading our paper on the ACM Digital Library or a PDF copy here.
@inproceedings{DBLP:conf/recsys/SankarWKS21,
author = {Aravind Sankar and Junting Wang and Adit Krishnan and Hari Sundaram},
title = {ProtoCF: Prototypical Collaborative Filtering for Few-shot Recommendation},
booktitle = {RecSys '21: Fifteenth {ACM} Conference on Recommender Systems, Amsterdam,
The Netherlands, 27 September 2021 - 1 October 2021},
pages = {166--175},
year = {2021},
url = {https://doi.org/10.1145/3460231.3474268},
doi = {10.1145/3460231.3474268}
}