In a nutshell
Can we make a trained machine learning model “forget” specific data without retraining from scratch?
With the growth of privacy regulations like GDPR and CCPA, machine unlearning—removing the influence of specific data from trained models—has become a key challenge. Existing “exact” unlearning methods, such as full retraining, are accurate but computationally expensive. Faster “approximate” methods often compromise accuracy or leave traces that can be detected by privacy attacks like membership inference.
In our latest work, we introduce Adversarial Machine UNlearning (AMUN), a novel approach that fine-tunes a model on specially crafted adversarial examples of the data to be forgotten. These examples are close to the original samples but labeled according to the model’s own mispredictions. Fine-tuning on them reduces the model’s confidence on the forget set—mimicking the effect of retraining—while minimizing changes to performance on other data. We evaluate the effectiveness of unlearning using SOTA Membership Inference Attacks (MIAs). We also show, even without access to the remaining samples, AMUN achieved low average gaps to retraining—outperforming all baselines. Finally, we introduced a theoretical analysis of our method that indicates the influencing factors on its effectiveness.
More details
Our first key observation by investigating the models retrained from scratch is that they treat the forget samples ($D_F$) the same as the (unseen) test samples. This has been overlooked by many works in machine unlearning which target low performance on the forget samples, which might lead to over-unlearning and making the model susseptible to membership inference attacks (MIAs). The following figure shows the confidence values when predicting the forget samples, match those derived when predicting the test samples.
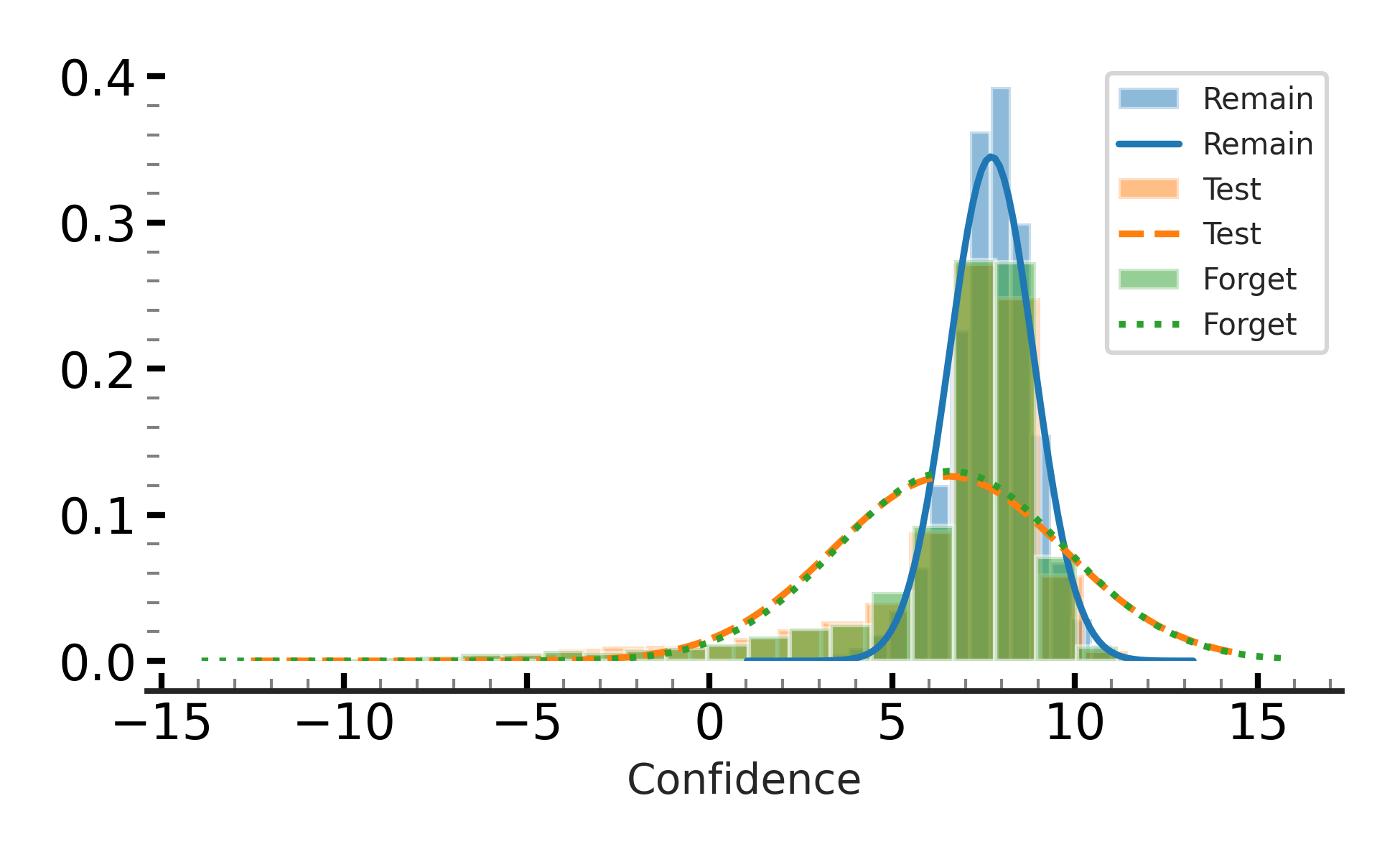
The main difference between the predictions on $D_T$ (unseen samples) and $D_R$ (observed samples) is that the model’s predictions are much more confident for the samples that it has observed compared to the unseen samples.
Our second key observation is that fine-tuning on adversarial examples with incorrect labels does not cause catastrophic forgetting, but it does lower prediction confidence for nearby samples. The following figure shows the effect of fine-tuning a trained ResNet-18 model on test accuracy when different sets of samples are used for fine-tuning the model. The orange curve shows the results when the model is fine-tuned on the forget samples (10%) of the training data, while the blue curve shows test accuracy when the model is fine-tuned on the forget samples and their corresponding adversarial samples (with the wrong labels). As the figure shows when adversarial examples are used for fine-tuning, the test accuracy of the model does not drop as using other datasts, such as forget samples with random labels (purple curve) or adversarial samples with other randomly chosen labels (red curve). For details about other curves see our paper.
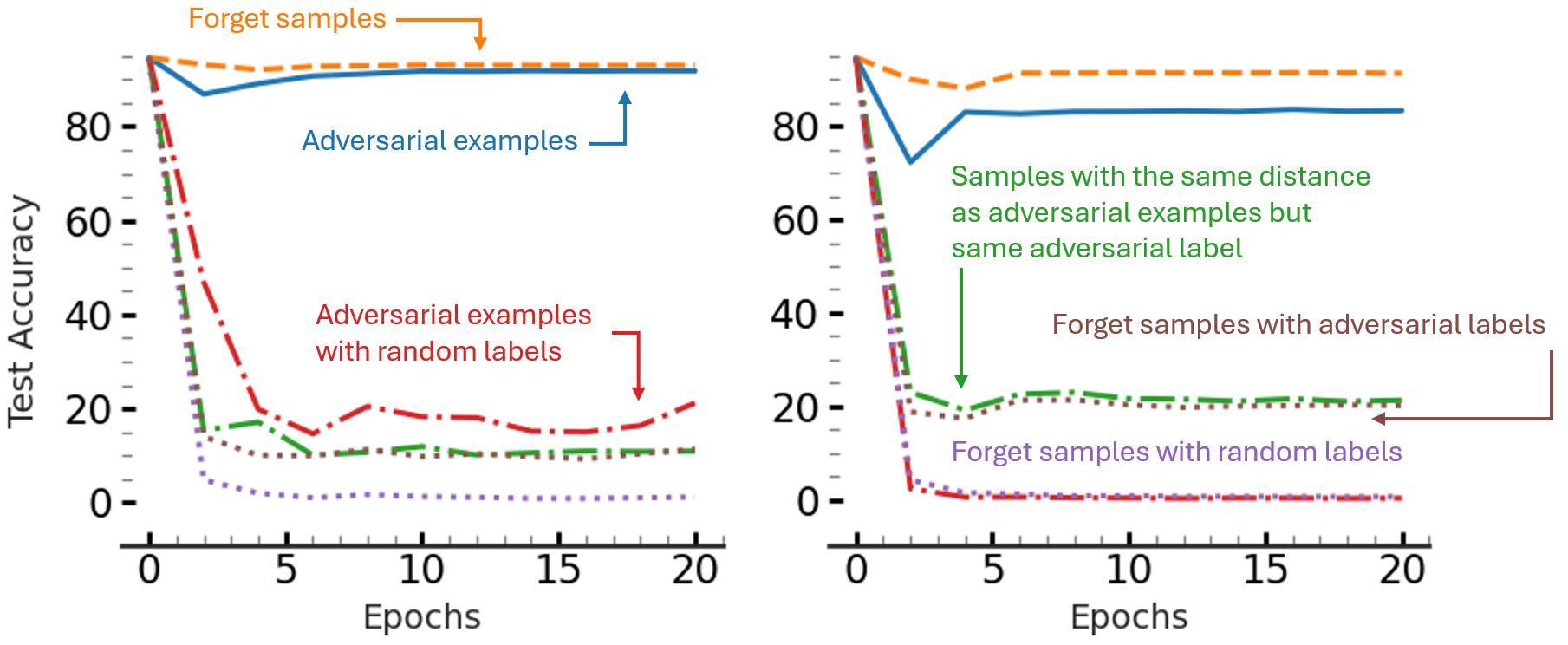
Fine-tuning a model on the adversarial examples does not lead to catastrophic forgetting!
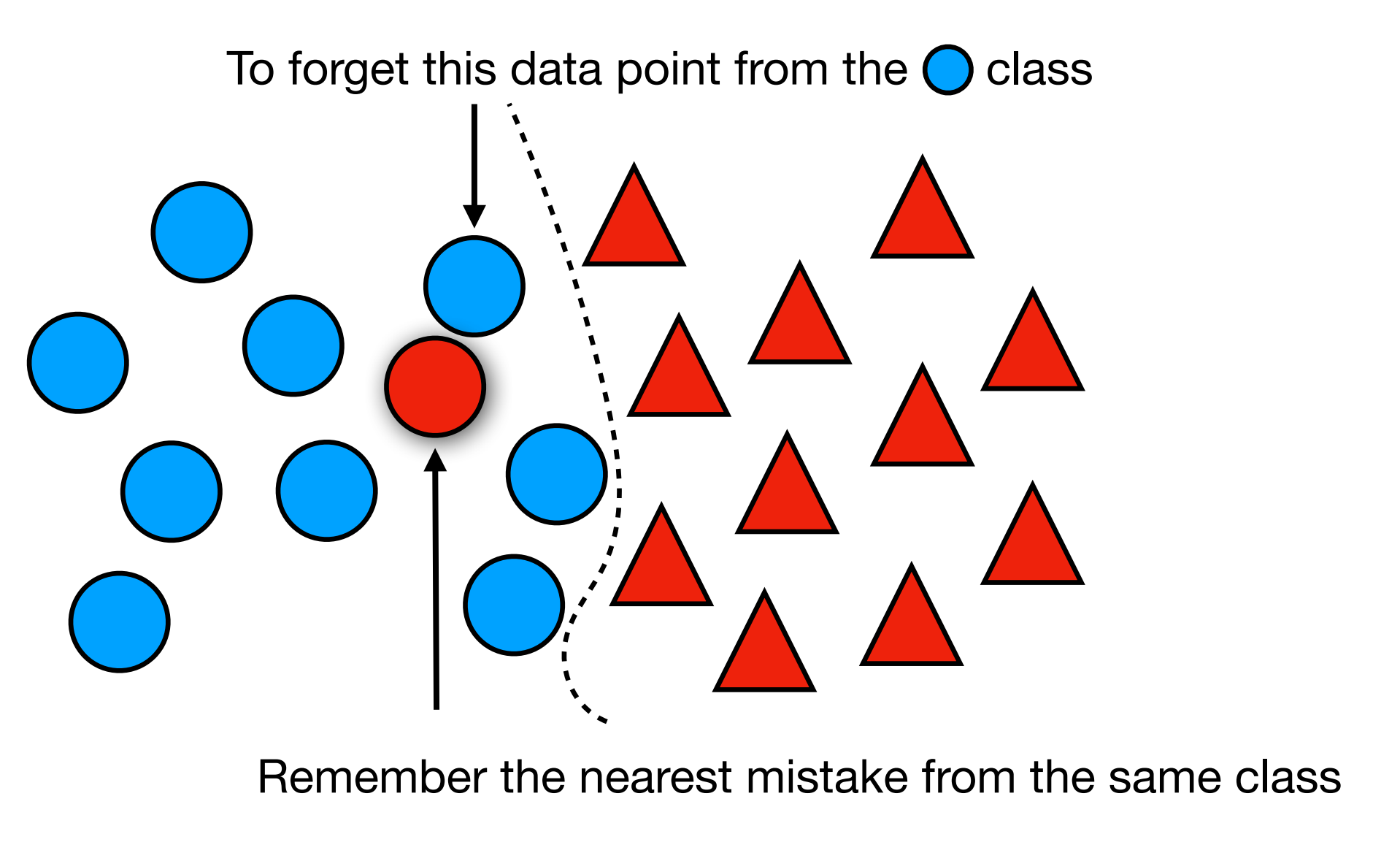
Inspired by these key observations, AMUN performs the following procedure to unlearn a given forget set:
- Finds the closest adversarial example for each sample in the forget set using an adversarial attack (e.g., PGD-50) and adds it to the set $D_{Adv}$.
- Fine-tunes the model on these examples (and, if available, the remaining data) to decrease the confidence of the model on samples in $D_F$ while localize decision boundary changes around those samples.
Through various experiments, we show that AMUN avoids the instability seen when directly maximizing loss or using random wrong labels and it is effective when even the remaining data is unavailable. Moreover, it does not lead to a degradation in test accuracy.
Results
We benchmarked AMUN against state-of-the-art unlearning methods like FT, RL, GA, BS, l1-Sparse, and SalUn on CIFAR-10 and Tiny Imagenet using ResNet-18. We evaluated using both older membership inference attacks (MIS) and a new, stronger attack (RMIA). The experiments included both forgetting of various portions of the dataset. All experiments show that AMUN achieves an unlearned model that is more similar to a model retrained from scratch; More specifically in smaller datasets such as CIFAR-10 it achieves a model with almost no gap with the retrained model.
The superiority of AMUN in comparison to existing unlearning methods become more apparent in the setting where there is no access to the remaining data, which is a more realisting setting as in practice due to various reasons such as privacy access to the remaining samples in the training data is not allowed. Moreover, we show that AMUN is more effective when handling successive unlearning requests.
Thoretical results in our paper shows the influencing factors that enhance the quality of unlearning with AMUN, including the strength of adversarial attack to find adversarial examples that are more similar to the original image while being mispredicted by the model with a higher confidence. They also show that as the forget set gets larger and the scratch-retrain model deviates further from the original image, it would be more difficult to recover a model that behaves similar to it by starting from the original model.
Resources
You can learn more about our work by reading our spotlight paper in ICML or a PDF copy here.
@inproceedings{ebrahimpournot,
title={Not All Wrong is Bad: Using Adversarial Examples for Unlearning},
author={Ebrahimpour-Boroojeny, Ali and Sundaram, Hari and Chandrasekaran, Varun},
booktitle={Forty-second International Conference on Machine Learning}
url = {https://openreview.net/pdf?id=BkrIQPREkn}
}