With the digitalization of a large fraction of the world, public information is now accessible and available from online social networks. Social experiments such as Milgram’s experiment and mental health-related experiments can now be efficiently be performed on online social networks. Interestingly, social scientists are increasingly interested in understanding the online behavior of the hidden populations such as people with mental illnesses, sex workers, and paid posters. Furthermore, businesses are interested in advertising their products selectively to specific groups of individuals. In this work, we shall see how these individuals with a hidden property that cannot be directly queried via online interfaces can be sampled.
The problem of sampling hidden population sampling is hard due to several reasons. One, online social networks such as Facebook and Twitter are vast, having billions of users. We are interested in only a specific subset of the population; thus it resembles the problem of searching a needle in haystack. Secondly, we are limited by the application programming interfaces that permit only a limited number of queries to be made. Thus, we need to define efficient samplers that can yield a significant fraction of these online hidden populations.
Related work
There are several potential strategies to search for hidden populations on a social network. One strategy is to exploit the graph structure as in Respondent Driven Sampling or web-crawling. At a high-level, a fundamental limitation of graph-based navigation strategy is that the local graph structure can limit our efforts to traverse the entire graph. In contrast, we can use the social network API to query entities using content (entity attributes) directly; the resulting entities that satisfy the query may be present anywhere on the social graph. One could also view the problem as reconstructing the underlying entity database of the social network. Unlike database reconstruction problem, our problem is much more restricted–we aim to obtain only a subset of the database. Query reformulation is another promising approach. Query reformulation systems typically use query log data to rewrite a query to maximize the number of relevant documents returned, where relevance is typically computed using the similarity of the query to the document. However, hidden properties are not directly accessible from the document text, making query reformulation challenging.
In this work, we shall use the public application interface, specifically the attributed search, to sample hidden populations.
Proposed Sampling Design
Before we delve into the design of the sampler, we first describe the high-level sampling framework through a representative example.
Consider a healthcare expert who is interested in using Twitter’s advanced search interface to understand the behavior of individuals that have some health issues (hidden property). The researcher uses a classifier or an expert to classify whether a sampled user belongs to the hidden population or not. The researcher uses advanced search attributes like language, location, dates, and keywords to sample Twitter users. As shown below, several possible queries can be formed using these attributes as shown below.
| hashtag | location | date |
|---|---|---|
| #Cubs | Chicago | Jan |
| #Cubs | Chicago | Jan |
| … | ||
| #Cubs | New York | Jan |
| #Dodgers | Los Angeles | March |
| #Yankees | New York | Jan |
We notice that there are a combinatorial number of different queries that can be formed using just a few attributes. Given the limited number of API queries available, we must design efficient sampling strategies that can quickly find the queries that will yield a high number of hidden population individuals.
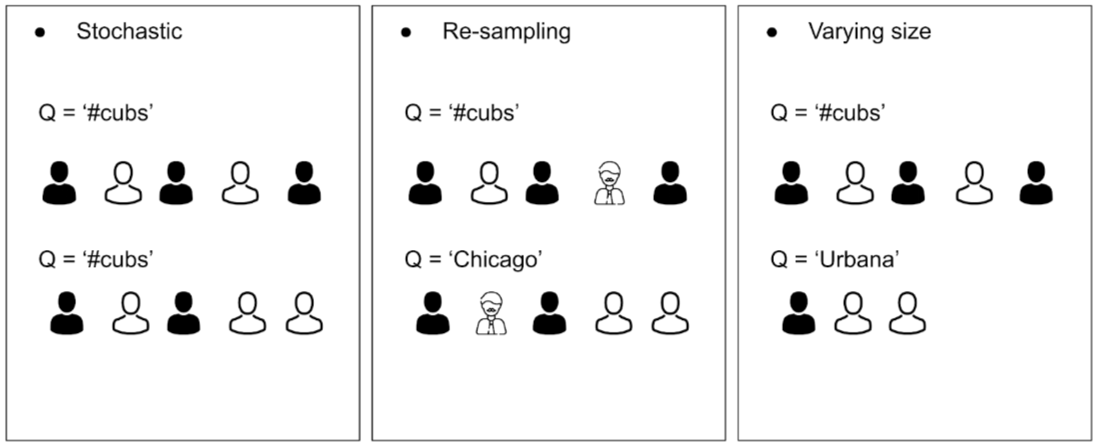
Next, we observe that Twitter’s Application Programming Interface (API) acts as a black-box and 1) may return different number of individuals from hidden population for the same query in different pages, 2) may return the same individual for different queries, and 3) may return fewer than expected or no individuals for some queries. The following figure shows a typical API that returns five individuals for a given query, where the hidden population entities are represented in black.
We address the problem of combinatorial search space by hierarchically organizing the query space in the form of a tree. Then, we use a decision-tree based search strategy that exploits the correlation between queryable attributes and hidden property to systematically explore the query space by expanding along high yielding decision-tree branches. To this effect, we propose a new attributed search based sampler DT-TMP that combines decision tree and thompson sampling to sample hidden populations from online social networks efficiently. Next, we describe the Thompson sampler followed by decision tree Thompson sampler.
Thompson (TMP) algorithm
Thompson sampling is a heuristic for choosing queries that address the exploration and exploitation tradeoff. Given a set of queries $q_1, q_2, \dots q_k$ , it estimates the expected reward of observing hidden population entities on issuing each query. Based on the estimate, Thompson sampling chooses the query that maximizes the expected reward with respect to a randomly drawn belief. We estimate the reward of a query using the following equation which takes into account the API’s black-box issues discussed above.
\[\mathbb{E}[r_{q}] = \underbrace{\frac{S_q}{S_q + F_q}}_\text{expected # targets} \cdot \underbrace{\frac{N_q-n_q}{N_q}}_\text{new} \cdot \underbrace{\Big( 1- \big(1 - \frac{1}{N_q} \big)^{m}}_\text{unique} \Big)\]DT-TMP (Decision Tree Thompson) algorithm
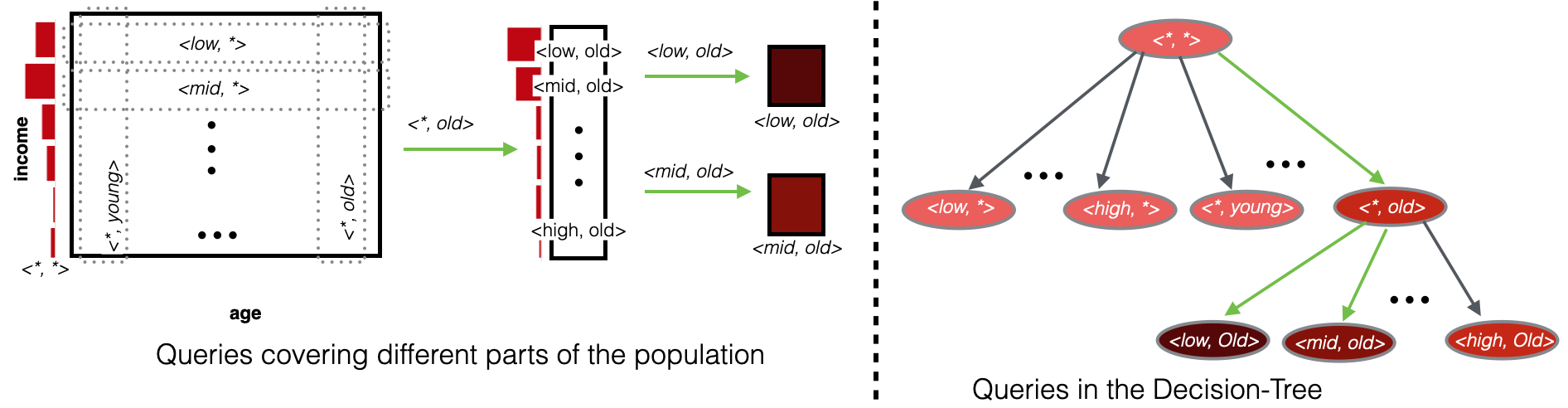
We show the workings of the DT-TMP algorithm through an illustrative example shown above. For a hidden population of ‘mental illness’ (represented in red color), the DT-TMP searches the population for the best combinatorial query comprising of two queryable attributes: income and age. It first uses <, *> query to find the best single attributed query from queries such as <Low, *> and <, Young>. Subsequently, it finds the best query <Low, *> along which it expands its query search. The decision tree on the right shows the query expansion with the query expansion along with green links.
In summary, DT-TMP maintains an estimate of discovering the number of hidden population entities for each query. It uses a Thompson sampling framework to address the exploration and exploitation tradeoff. Furthermore, DT-TMP organizes the query in a tree fashion where general queries are near the root and specific queries are near the leaf. This organization allows DT-TMP to reject poor yielding branches or poor yielding queries (exploiting the correlation between attributes and hidden property) and greedily exploit the high yielding branches.
How does DT-TMP perform in practice?
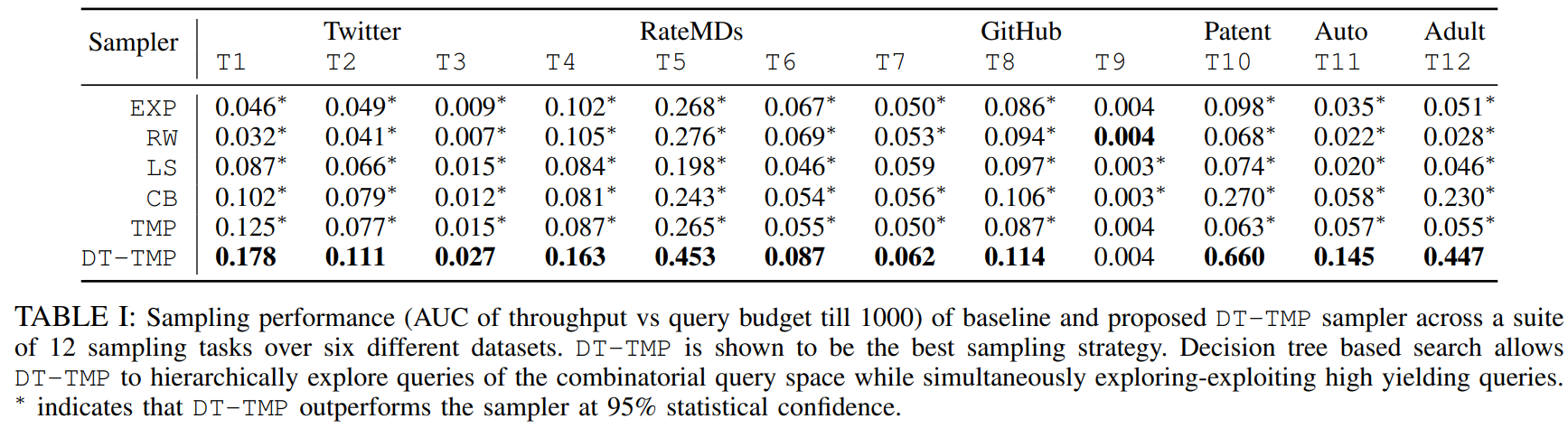
We test our algorithm against standard state-of-the-art hidden population samplers on three offline and three online datasets for a multitude of twelve sampling tasks. The following table illustrates the sampling performance of DT-TMP across several tasks (example, T1: female Twitter users, T2: Twitter users having verified account, T4: doctors rated 5-star on RateMD).
Future directions
While a number of previous studies have focused on specific models for sampling, for example sampling using graph APIs or sampling using attributed search or sampling through keyword-based search, we need to develop models that can use richer query models that exploits the usefulness of different models while considering the sampling cost tradeoffs. Nazi et al.’s work is one of the pioneering works in this direction. Furthermore, real-world samplers suffer from the problem of inaccuracy from the classifiers and missing and noisy information. A more robust sampling methodology is needed that can address the above problems. Furthermore, we could use the attributed search not just to sample hidden population nodes efficiently but also estimate properties of interest like distribution and correlation metrics in a sample efficient manner. A theoretical understanding of the problem’s hardness is currently missing.
Further Information
This blog is based on the paper,
@inproceedings{kumar2019hierarchical,
title = {Hierarchical multi-armed bandits for discovering hidden populations},
author = {Kumar, Suhansanu and Gao, Heting and Wang, Changyu and Chang, Kevin Chen-Chuan and Sundaram, Hari},
booktitle = {Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining},
pages = {145--153},
year = {2019}
}